

Les organisations qui déploient Data Cloud sans maîtriser Identity Resolution obtiennent des Unified Individuals fragmentés, des segments inexacts et des agents Agentforce qui raisonnent sur des données contradictoires. Ce salesforce data cloud identity resolution guide couvre l’architecture réelle : pas la documentation produit, mais les décisions qui déterminent si votre unification tient à l’échelle.
Ce que fait réellement Identity Resolution (et ce qu’on lui demande à tort)
Identity Resolution résout un problème précis : un même individu existe sous plusieurs identités dans vos systèmes sources. Un email dans votre CRM, un numéro de téléphone dans votre ERP, un cookie dans votre plateforme e-commerce. Identity Resolution construit le pont entre ces fragments pour produire un Unified Individual, l’entité centrale autour de laquelle Data Cloud organise tout le reste.
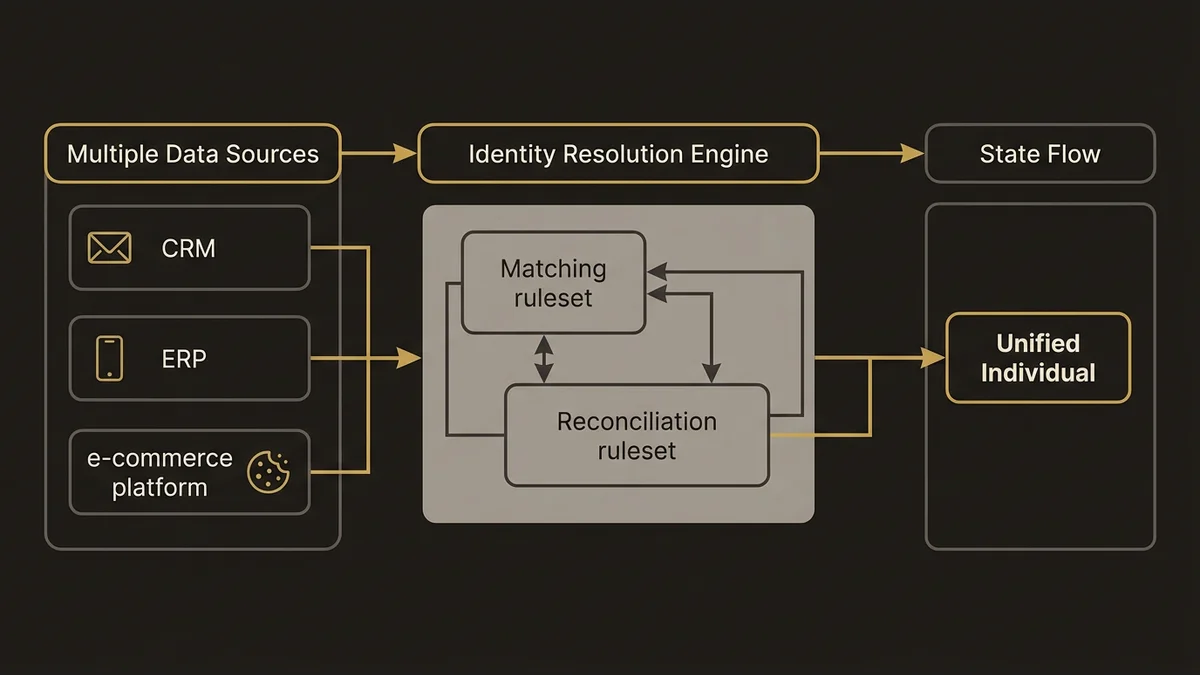
Le problème n’est pas la technologie. Le problème, c’est que la plupart des équipes traitent Identity Resolution comme une configuration à cocher plutôt que comme une décision architecturale structurante.
Concrètement, Identity Resolution opère en deux temps. D’abord, les rulesets de correspondance (matching) comparent les attributs entre Data Model Objects pour identifier les enregistrements qui appartiennent probablement au même individu. Ensuite, les rulesets de réconciliation (reconciliation) décident quelle valeur retenir quand plusieurs sources fournissent des données contradictoires pour le même attribut.
Ces deux étapes sont indépendantes et configurables séparément. C’est là que les architectures divergent.
L’architecture des rulesets : déterministe ou probabiliste
Deux approches existent pour le matching. Une seule est adaptée à la majorité des contextes enterprise.

Le matching déterministe fusionne les enregistrements quand un attribut exact correspond : même adresse email, même numéro de téléphone normalisé, même identifiant CRM. Zéro ambiguïté, zéro faux positif. La contrepartie : si un client a changé d’email entre deux achats, les deux enregistrements restent séparés.
Le matching probabiliste calcule un score de similarité sur plusieurs attributs combinés : prénom, nom, code postal, date de naissance. Il fusionne quand le score dépasse un seuil configurable. Plus de couverture, mais des faux positifs possibles, deux individus distincts fusionnés par erreur.
La plupart des architectes enterprise commencent par le déterministe pur. C’est la bonne décision. Voici pourquoi : un faux positif dans Identity Resolution propage l’erreur à tous les systèmes en aval. Un agent Agentforce qui raisonne sur un profil fusionné par erreur prend des décisions sur la mauvaise personne. À l’échelle de plusieurs millions de profils, même un taux d’erreur de 0,1% représente des milliers de clients mal servis.
Le probabiliste se justifie dans des contextes spécifiques : données historiques sans identifiant commun, migration depuis des systèmes legacy sans clé de jointure propre. Dans ces cas, déployez-le en parallèle du déterministe, sur un périmètre délimité, avec une validation manuelle sur un échantillon avant de l’activer en production.
Réconciliation : la décision que personne ne documente
La réconciliation est la partie d’Identity Resolution que les équipes sous-estiment systématiquement. Quand deux sources fournissent des valeurs différentes pour le même attribut d’un Unified Individual, laquelle retenir ?
Data Cloud propose plusieurs stratégies de réconciliation : la source la plus récente, la source la plus fréquente, la source prioritaire (selon un ordre que vous définissez). Chaque stratégie a des implications métier directes.
Prenez l’adresse email. Si votre stratégie est “source la plus récente” et qu’un client met à jour son email dans votre portail self-service, cette valeur écrase celle de votre CRM. C’est peut-être ce que vous voulez. Mais si votre CRM est la source de vérité contractuelle pour les communications réglementées, vous venez de créer un problème de conformité.
La règle pratique : définissez une hiérarchie de sources par type d’attribut, pas une hiérarchie globale. L’email de contact peut venir du portail. L’adresse de facturation vient de l’ERP. Le statut de consentement vient exclusivement de votre plateforme de gestion des préférences. Cette granularité est configurée dans les rulesets de réconciliation, attribut par attribut.
Pour les organisations avec des contraintes RGPD strictes, le statut de consentement mérite un traitement particulier : source unique, pas de réconciliation probabiliste, traçabilité complète. Un Unified Individual dont le consentement est ambigu ne doit pas être activable dans les Segments.
Data Streams et qualité des données en entrée
Identity Resolution ne corrige pas les données en entrée. Elle amplifie leur qualité, dans les deux sens.
Des données propres en entrée produisent des Unified Individuals fiables. Des données dégradées, des emails mal formatés, des numéros de téléphone sans indicatif pays, des noms avec des caractères spéciaux non normalisés, produisent des profils fragmentés ou des fusions incorrectes.
La normalisation se fait en amont, dans les Data Streams ou dans les transformations appliquées aux Data Model Objects avant que les rulesets s’exécutent. En pratique, cela signifie définir des règles de nettoyage pour chaque attribut utilisé dans le matching : format E.164 pour les téléphones, lowercase pour les emails, suppression des espaces superflus dans les noms.
Un pattern courant dans les organisations enterprise avec plusieurs systèmes sources : créer un DMO intermédiaire normalisé pour chaque entité Contact, alimenté par les Data Streams bruts, avant de l’exposer à Identity Resolution. Ce DMO intermédiaire absorbe la variabilité des formats sources sans polluer la logique de matching.
Cette approche a un coût en complexité de modèle de données. Elle se justifie dès que vous avez plus de trois sources hétérogènes ou des données historiques avec des conventions de formatage inconsistantes.
Ce que les Data Graphs changent à l’équation
Une fois les Unified Individuals construits, les Data Graphs permettent de matérialiser des vues pré-calculées qui joignent le profil unifié à ses données transactionnelles, comportementales et contextuelles.
L’impact sur Identity Resolution est indirect mais structurant : un Data Graph mal conçu peut contourner l’unification. Si vous construisez un Data Graph qui joint directement les enregistrements sources sans passer par le Unified Individual, vous perdez le bénéfice de la résolution d’identité pour tous les cas d’usage en aval, notamment l’alimentation des agents Agentforce via les Actions.
L’architecture correcte : les Data Graphs s’appuient sur le Unified Individual comme entité centrale. Les jointures partent du profil unifié vers les données transactionnelles, pas l’inverse. Cette contrainte semble évidente sur le papier. En pratique, sous la pression des délais, les équipes construisent des Data Graphs ad hoc qui court-circuitent l’unification pour “aller plus vite”. Cela fonctionne jusqu’au moment où vous devez activer ces données dans un Segment ou les exposer à un agent. À ce stade, le modèle doit être reconstruit.
Pour approfondir l’architecture Data Cloud dans son ensemble, l’article sur l’implémentation Data Cloud couvre les décisions de modèle de données en amont de l’Identity Resolution.
Calculated Insights et Segments : la validation de l’unification
La qualité d’Identity Resolution se mesure en aval, pas dans les logs de configuration.
Deux indicateurs pratiques. D’abord, le taux de fragmentation : combien de Unified Individuals ont plus de cinq enregistrements sources associés ? Un taux élevé indique soit une sur-fusion (le matching est trop permissif), soit des données sources de mauvaise qualité. Ensuite, le taux de singletons : combien de Unified Individuals n’ont qu’un seul enregistrement source ? Un taux élevé indique une sous-fusion, des individus qui auraient dû être unifiés ne le sont pas.
Les Calculated Insights permettent de calculer ces métriques directement dans Data Cloud et de les monitorer dans le temps. Configurez ces insights dès le déploiement initial. Ils servent de tableau de bord de santé pour votre unification et détectent les dérives quand de nouvelles sources sont intégrées.
Pour les Segments, une règle simple : ne créez pas de Segment sur des attributs non réconciliés. Si un attribut n’a pas de stratégie de réconciliation définie, sa valeur sur le Unified Individual est indéterminée. Un Segment basé sur cet attribut produira des résultats inconsistants selon l’ordre d’exécution des rulesets.
La décision qui détermine la suite
L’architecture Identity Resolution que vous déployez aujourd’hui détermine si Agentforce peut raisonner sur des profils fiables dans 18 mois. Un agent qui accède à des Unified Individuals fragmentés ou sur-fusionnés ne peut pas produire de recommandations cohérentes, quelle que soit la qualité de ses Topics et Actions.
La décision actuelle n’est pas technique. C’est une décision de gouvernance : qui est propriétaire de la hiérarchie des sources ? Qui valide les rulesets de réconciliation pour les attributs sensibles ? Qui monitore les métriques de qualité en production ?
Sans réponse à ces trois questions avant le déploiement, Identity Resolution devient un paramètre de configuration que personne ne maintient. Les Unified Individuals dérivent. Les Segments deviennent inexacts. Et les cas d’usage IA qui dépendent de ces profils produisent des résultats que personne ne peut expliquer.
Pour les organisations qui évaluent l’architecture complète avant de déployer, la page services Data Cloud et Multi-Cloud détaille les patterns d’intervention adaptés à chaque contexte.
Points Clés
- Identity Resolution produit des Unified Individuals fiables uniquement si les rulesets de matching et de réconciliation sont configurés séparément, avec une logique métier explicite pour chaque attribut.
- Le matching déterministe est le point de départ correct pour les contextes enterprise. Le probabiliste se déploie sur un périmètre délimité, avec validation, pas comme configuration par défaut.
- La réconciliation doit être définie attribut par attribut, pas globalement. Le statut de consentement exige une source unique et une traçabilité complète pour la conformité RGPD.
- Les Data Graphs doivent s’appuyer sur le Unified Individual comme entité centrale. Court-circuiter l’unification pour accélérer la construction d’un Data Graph crée une dette architecturale qui bloque les cas d’usage IA en aval.
- La qualité d’Identity Resolution se mesure par deux métriques en production : le taux de fragmentation et le taux de singletons. Ces Calculated Insights doivent être configurés dès le déploiement initial, pas après la première dérive détectée.
