

La plupart des organisations qui déploient plusieurs clouds Salesforce en parallèle finissent par construire une toile d’araignée d’intégrations point-à-point qu’elles ne peuvent plus démêler deux ans plus tard. L’intégration multi-cloud Salesforce MuleSoft est présentée comme la solution naturelle à ce problème; mais la façon dont elle est architecturée détermine si vous gagnez en agilité ou si vous ajoutez simplement une couche d’abstraction supplémentaire à votre dette technique.
Le choix architectural que vous faites aujourd’hui sur la topologie d’intégration conditionne directement votre capacité à déployer Agentforce ou Data Cloud dans 18 mois.
Pourquoi l’Intégration Point-à-Point Échoue à l’Échelle Multi-Cloud
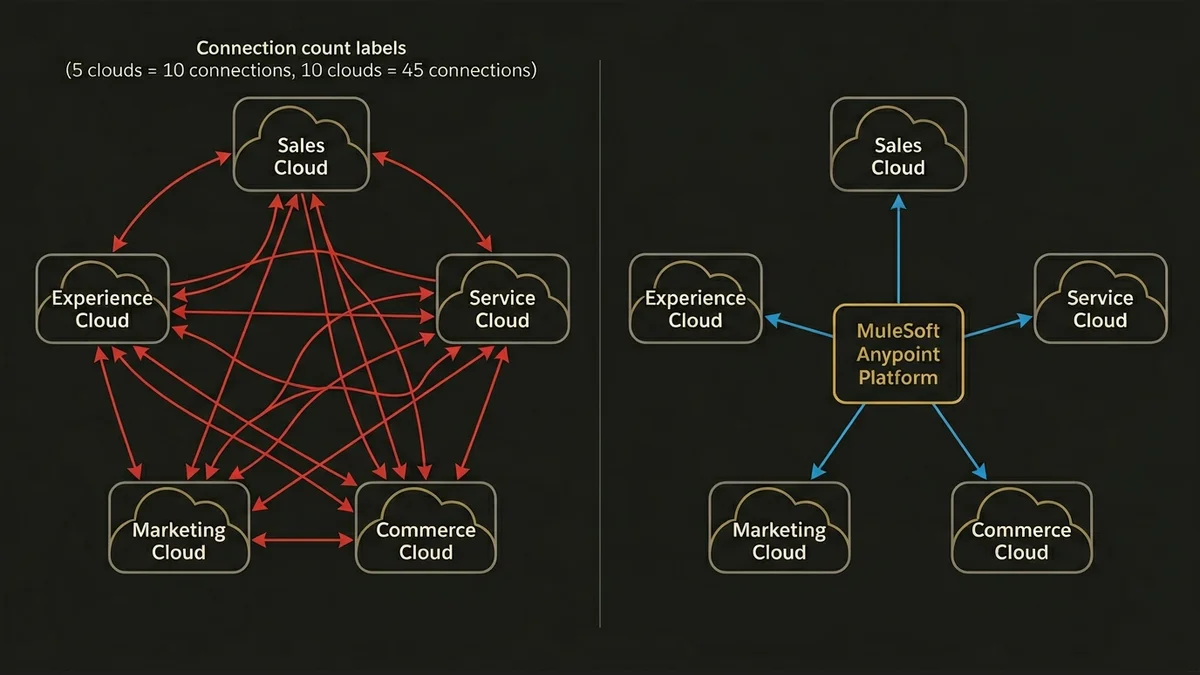
Dans les organisations avec plus de cinq clouds Salesforce actifs (Sales Cloud, Service Cloud, Commerce Cloud, Marketing Cloud, Experience Cloud), le nombre de connexions directes possibles croît de façon quadratique. Cinq clouds, c’est potentiellement dix connexions directes. Dix clouds, c’est quarante-cinq. En pratique, les équipes qui gèrent ces environnements sans couche d’intégration centralisée passent entre 30 et 40% de leur temps à déboguer des flux de données incohérents entre clouds.
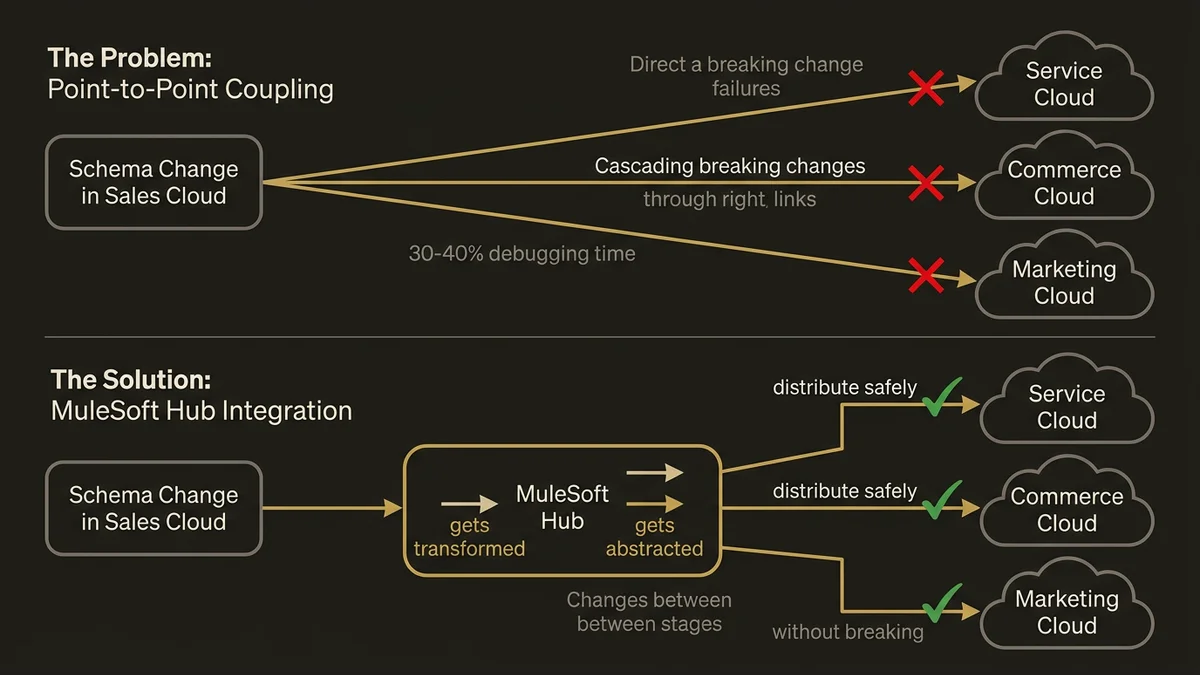
Le problème fondamental n’est pas technique, il est topologique. Chaque connexion directe entre deux clouds crée un couplage fort : quand le schéma de données d’un côté change, l’autre côté casse. Dans un contexte multi-cloud Salesforce, où les releases trimestrielles peuvent modifier des objets standard, ce couplage devient une source permanente d’instabilité.
MuleSoft résout ce problème en imposant une topologie en étoile (hub-and-spoke) via Anypoint Platform. Mais l’architecture hub-and-spoke n’est pas gratuite : elle introduit un point de défaillance unique et une latence supplémentaire. La question n’est donc pas “faut-il utiliser MuleSoft ?” mais “quels flux doivent passer par MuleSoft et lesquels doivent rester natifs Salesforce ?”
Quand Utiliser MuleSoft vs les Connecteurs Natifs Salesforce
La réponse courte : MuleSoft pour les systèmes externes, les connecteurs natifs et Data Cloud pour les flux intra-Salesforce.
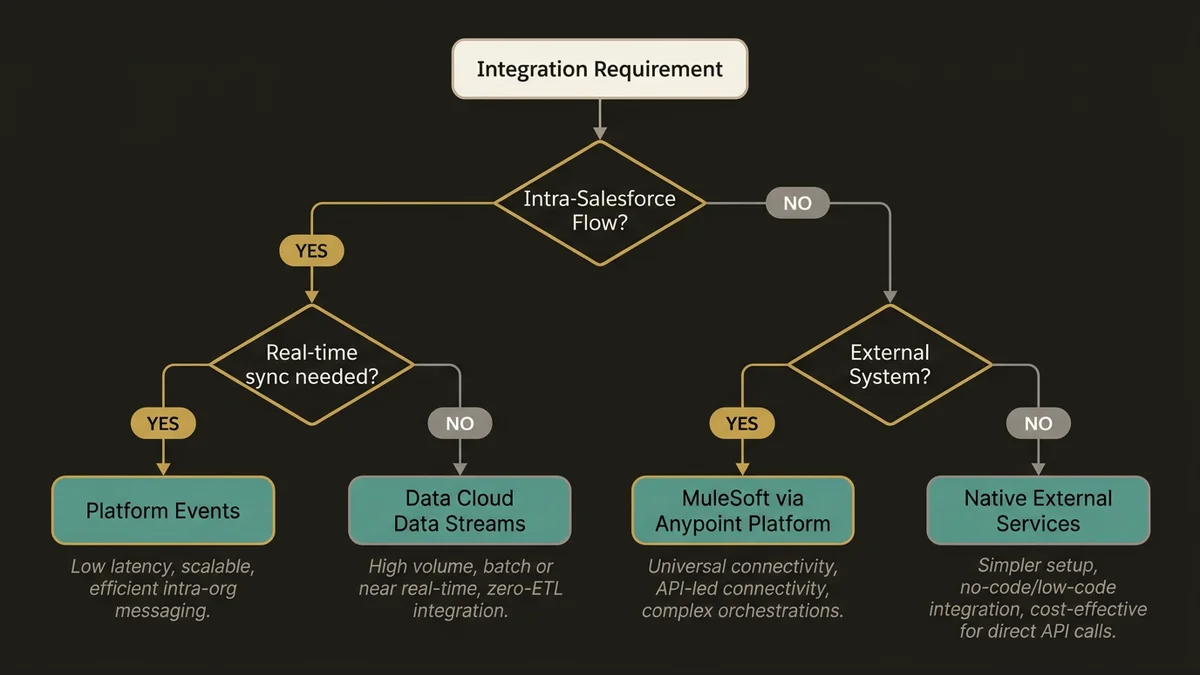
Salesforce a investi massivement dans ses capacités d’intégration natives. Data Cloud Data Streams peut ingérer des données depuis n’importe quel cloud Salesforce via des connecteurs dédiés, sans passer par MuleSoft. Les Platform Events permettent une communication pub/sub en temps réel entre clouds avec une latence inférieure à la seconde. External Services expose des APIs REST directement dans Flow sans code.
L’erreur classique dans les ESN françaises est de router tous les flux via MuleSoft par défaut, y compris les synchronisations entre Sales Cloud et Service Cloud qui pourraient être gérées nativement. Résultat : une facture MuleSoft qui explose, une latence inutile, et une équipe d’intégration qui devient un goulot d’étranglement pour chaque évolution métier.
La règle architecturale qui fonctionne en pratique : MuleSoft intervient quand au moins un des systèmes impliqués est externe à l’écosystème Salesforce, quand la transformation de données est complexe (mapping multi-niveaux, agrégation, orchestration conditionnelle), ou quand la gouvernance des APIs nécessite un point de contrôle centralisé pour la sécurité et le monitoring.
Pour les flux purement intra-Salesforce, Data Cloud avec ses Data Streams et ses Data Model Objects (DMOs) est architecturalement supérieur à MuleSoft. Les DMOs normalisent les données à l’ingestion, ce qui élimine les transformations répétitives que MuleSoft devrait autrement gérer à chaque synchronisation.
L’Architecture qui Fonctionne : API-Led Connectivity avec des Limites Claires
L’API-Led Connectivity de MuleSoft définit trois couches : Experience APIs (adaptées à chaque consommateur), Process APIs (orchestration métier), System APIs (accès aux systèmes sources). Cette taxonomie est correcte mais souvent mal appliquée.
Dans les organisations avec plus de 3 000 points de contact retail ou des architectures multi-cloud complexes, la couche Process API devient critique. C’est là que réside la logique d’orchestration qui coordonne plusieurs systèmes : une commande Commerce Cloud qui déclenche une mise à jour Service Cloud, une notification Marketing Cloud, et une écriture dans le système ERP. Sans cette couche, cette logique se retrouve éparpillée dans des Flows Salesforce, des Apex triggers et des scripts MuleSoft sans cohérence.
[Commerce Cloud] ──► [System API: Commerce]
│
[ERP SAP] ────────► [System API: ERP] ──► [Process API: Order Orchestration] ──► [Experience API: Service Agent]
│
[Service Cloud] ──► [System API: CRM]Ce pattern impose une discipline : chaque System API ne connaît qu’un seul système source. Chaque Process API ne connaît que des System APIs, jamais directement les systèmes sources. Cette séparation des responsabilités est ce qui rend le système maintenable quand un système source change.
L’écueil le plus fréquent est de créer des Process APIs qui appellent directement des endpoints externes, court-circuitant les System APIs pour “gagner du temps”. En pratique, cela reconstruit exactement le couplage fort que l’architecture API-Led était censée éliminer.
Pour approfondir les patterns d’architecture multi-cloud, l’article sur les patterns d’architecture multi-cloud Salesforce détaille les topologies de déploiement selon la maturité organisationnelle.
Data Cloud comme Couche d’Intégration Sémantique
Un changement architectural majeur que beaucoup d’organisations ratent : Data Cloud n’est pas seulement une plateforme de données client, c’est une couche d’intégration sémantique pour les données Salesforce.
L’Identity Resolution de Data Cloud, avec ses rulesets de correspondance configurables, résout un problème que MuleSoft ne peut pas résoudre proprement : l’unification des identités client à travers plusieurs clouds. Un client qui existe dans Commerce Cloud avec un email, dans Service Cloud avec un numéro de téléphone, et dans Marketing Cloud avec un cookie anonyme devient un Unified Individual dans Data Cloud sans qu’une seule ligne de code d’intégration soit nécessaire.
Les Calculated Insights permettent ensuite de calculer des métriques agrégées (valeur vie client, score d’engagement, propension à l’achat) directement sur ce profil unifié. Ces métriques sont ensuite disponibles pour tous les clouds Salesforce via les Data Graphs, qui sont des vues matérialisées pré-calculées optimisées pour les jointures en temps réel.
La latence typique pour l’activation Data Cloud en temps réel, dans des architectures enterprise bien configurées, est de 2 à 5 minutes pour la propagation d’un événement depuis l’ingestion jusqu’à la disponibilité dans un Segment. Pour les cas d’usage qui nécessitent une réactivité inférieure à la minute, les Platform Events restent la bonne réponse.
L’architecture qui émerge dans les déploiements matures combine les deux : MuleSoft pour l’intégration des systèmes externes et la gouvernance des APIs, Data Cloud pour l’unification sémantique des données client intra-Salesforce, et les Platform Events pour les notifications temps réel entre clouds. Ces trois couches ne se substituent pas, elles se complètent.
Les Décisions Architecturales qui Engagent l’Avenir
Deux décisions prises en début de projet ont des conséquences disproportionnées sur la capacité à évoluer.
La première concerne le modèle de données canonique. MuleSoft impose de définir un modèle de données canonique dans la couche Process API : c’est le format pivot dans lequel toutes les données sont transformées avant d’être routées. Si ce modèle est calqué sur le modèle de données d’un système source spécifique (souvent l’ERP ou le CRM historique), chaque nouveau système source nécessite une transformation complexe. Le bon choix est d’aligner le modèle canonique sur les DMOs de Data Cloud, qui suivent eux-mêmes des standards sectoriels (retail, financial services, healthcare). Cela crée une cohérence naturelle entre la couche d’intégration MuleSoft et la couche de données Data Cloud.
La deuxième décision concerne la gestion des erreurs et la résilience. Dans une architecture multi-cloud, une défaillance partielle est inévitable. La question est de savoir si votre architecture est conçue pour la détecter, l’isoler et se remettre automatiquement. Les patterns Dead Letter Queue dans MuleSoft, combinés aux Platform Events pour les notifications d’erreur et aux Flow orchestration pour les processus de compensation, constituent l’architecture de résilience standard. Les organisations qui ne définissent pas ces patterns dès le départ se retrouvent à gérer des incohérences de données manuellement lors des premières pannes.
Si votre organisation envisage de déployer Agentforce sur cette infrastructure, la cohérence des données entre clouds devient critique : l’Atlas Reasoning Engine d’Agentforce prend des décisions basées sur les données disponibles au moment de l’invocation. Des données incohérentes entre Sales Cloud et Service Cloud produisent des réponses d’agent incohérentes, ce qui érode la confiance des utilisateurs plus rapidement que n’importe quel bug fonctionnel.
Pour les organisations qui évaluent comment positionner MuleSoft par rapport aux capacités natives de Data Cloud, la page /services/data-cloud-architecture détaille les patterns d’architecture selon la complexité du paysage applicatif.
Points Clés
- L’intégration multi-cloud Salesforce MuleSoft n’est pas une décision binaire : MuleSoft gère les systèmes externes et la gouvernance des APIs, Data Cloud gère l’unification sémantique intra-Salesforce, les Platform Events gèrent le temps réel. Ces trois couches sont complémentaires, pas substituables.
- Router tous les flux via MuleSoft par défaut est la principale source de surcoût et de latence inutile dans les architectures multi-cloud. Les flux purement intra-Salesforce doivent utiliser les connecteurs natifs et Data Streams.
- Aligner le modèle de données canonique MuleSoft sur les DMOs de Data Cloud dès le départ réduit la complexité de transformation de façon significative et prépare l’architecture pour les cas d’usage Agentforce.
- La latence d’activation Data Cloud en temps réel est de 2 à 5 minutes dans des architectures enterprise bien configurées. Pour les cas d’usage sub-minute, les Platform Events restent la bonne réponse.
- Les patterns de résilience (Dead Letter Queue, compensation via Flow) doivent être définis avant le premier déploiement en production, pas après la première panne.
