
Most architects are treating the Cimulate acquisition as a UX story. It isn’t. The Cimulate Commerce Cloud data architecture implications run deeper than conversational search; they reach into how product catalogs are structured, how attributes are modeled, and what your integration layer needs to support before any AI layer can function.
The surface question is: how does Cimulate’s AI understand products well enough to answer natural language queries? The structural answer is: it requires a catalog data model that most Commerce Cloud implementations don’t have.
Why Standard Catalog Models Break Under Semantic Load
A typical B2C Commerce Cloud catalog is optimized for browse and filter. Products have categories, attributes, and variants. The attribute model is flat; color, size, material; and the relationships between products are either explicit (cross-sells, up-sells) or absent. That works for faceted search. It doesn’t work for semantic retrieval.
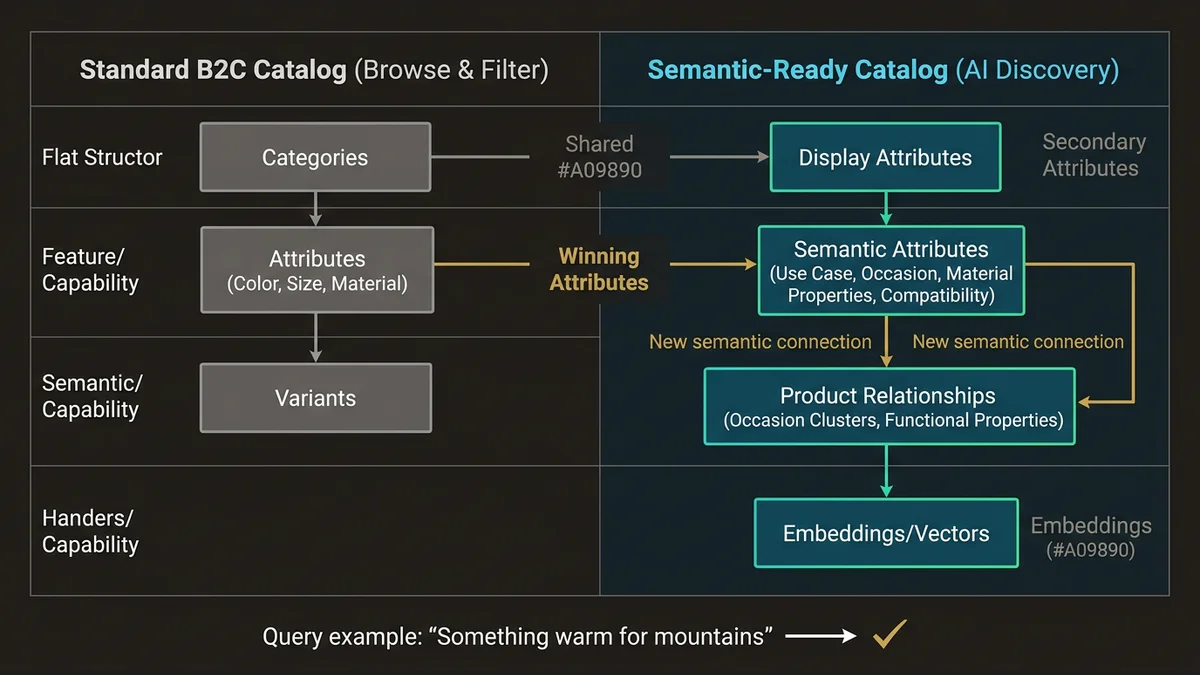
Cimulate’s approach to product discovery depends on understanding what a product is in context, not just what attributes it carries. A query like “something warm for a weekend in the mountains” requires the system to reason across product type, use case, material properties, and occasion. None of those dimensions exist as structured fields in a standard catalog. They exist, at best, as unstructured text in product descriptions.
The architecture problem is that unstructured text is expensive to reason over at query time. The systems that handle this well pre-compute semantic representations; embeddings, enriched attribute sets, or materialized product graphs; so that retrieval is fast and contextually accurate. That pre-computation requires a catalog data model that supports it.
In practice, this means the acquisition forces a question that most Commerce Cloud teams have deferred: is your product catalog a source of truth, or just a display layer?
What the Catalog Data Model Actually Needs to Support
Three structural changes matter here, and they compound.
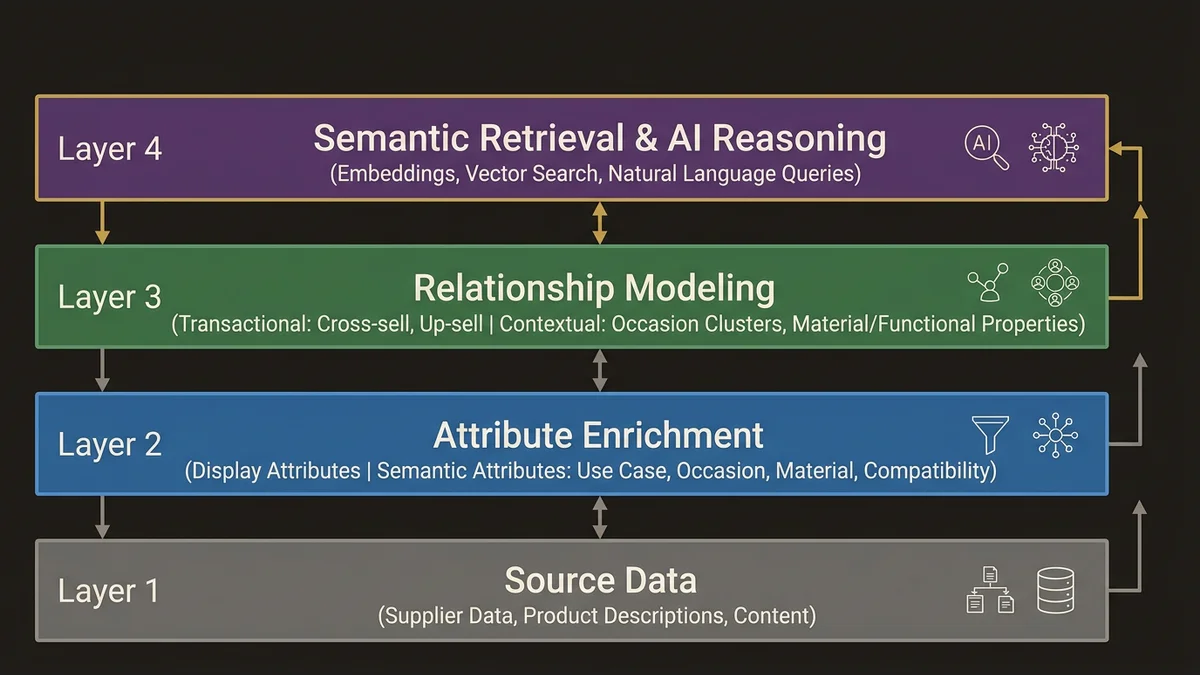
Attribute enrichment at the product level. Flat attribute models need to become richer without becoming unmanageable. The pattern that works is separating display attributes (what the storefront renders) from semantic attributes (what the AI reasons over). Semantic attributes include use-case tags, occasion mappings, material properties beyond the label, and compatibility signals. These don’t come from merchandising teams; they’re generated through a combination of supplier data, content enrichment pipelines, and increasingly, AI-assisted tagging at catalog ingestion time.
Relationship modeling between products. Cross-sells and up-sells are transactional relationships. Semantic discovery needs contextual relationships: products that belong to the same “occasion cluster,” products that share material or functional properties, products that complete an outfit or a room. These relationships need to be first-class entities in the data model, not afterthoughts in the storefront layer. In Data Cloud terms, this maps to Data Model Objects that represent product-to-product relationships with typed edges, not just foreign keys.
Variant structure that preserves semantic coherence. The standard Commerce Cloud variant model groups variants under a master product. That’s fine for display. For semantic retrieval, a “black wool coat in size 12” and a “camel wool coat in size 8” may need to be retrievable as distinct semantic entities, not just as variant combinations. The architecture that handles this correctly separates the variant display model from the semantic retrieval model, and keeps them in sync through a well-defined pipeline rather than treating them as the same object.
None of this is optional if Cimulate’s capabilities are going to function at the product depth that makes them useful. Shallow catalogs produce shallow AI responses.
How Data Cloud Fits Into This Architecture
The integration architecture question that follows from the catalog model question is: where does the enriched product data live, and how does it flow?
The pattern emerging in orgs that are ahead of this is to treat Data Cloud as the semantic layer for product data, not just for customer data. Product records ingested via Data Streams, enriched through Calculated Insights, and materialized into Data Graphs give the AI layer a pre-computed, relationship-aware view of the catalog. Identity Resolution, typically used for customer profiles, has an analog here: product deduplication and canonical record resolution across catalog sources (supplier feeds, ERP, PIM systems) before data reaches Commerce Cloud.
This matters because most Commerce Cloud implementations have catalog data coming from multiple upstream systems. A PIM handles master data. An ERP carries pricing and availability. Supplier feeds carry enriched content that may or may not be normalized. Without a unification layer, the AI is reasoning over inconsistent, partially duplicated product data; and the output quality reflects that.
The architecture that works here positions Data Cloud between the upstream catalog sources and the AI reasoning layer. Commerce Cloud remains the transactional system of record for the storefront. Data Cloud carries the enriched, unified, semantically structured product graph that Agentforce and Cimulate’s capabilities query against.
That’s a meaningful shift from how most teams have scoped Data Cloud in commerce contexts. The Data Cloud and multi-cloud architecture work that was previously focused on customer 360 now needs to extend to product 360 with the same rigor.
The Integration Layer Priorities That Change
Before the acquisition, Commerce Cloud integration architecture was primarily about order management, inventory sync, and storefront personalization. The Cimulate acquisition shifts the priority stack.
Real-time catalog sync becomes critical. If the AI layer is reasoning over a product graph in Data Cloud, that graph needs to reflect current availability, pricing, and attribute state. A 24-hour batch sync that was acceptable for reporting is not acceptable for a conversational shopping experience where a customer asks “what’s available in my size under $200?” and gets an answer based on yesterday’s inventory.
The latency target for catalog updates flowing from Commerce Cloud through to the AI reasoning layer needs to be measured in minutes, not hours. Platform Events are the right mechanism for triggering downstream updates when catalog records change. The pipeline from Commerce Cloud to Data Cloud via Data Streams needs to be event-driven, not scheduled.
MuleSoft’s role in this architecture is upstream normalization. Supplier feeds, PIM exports, and ERP pricing data arrive in inconsistent formats. MuleSoft normalizes them into a canonical product schema before they reach Data Cloud. That canonical schema is what makes the semantic enrichment reliable; garbage in, garbage out applies to AI reasoning as much as it applies to reporting.
The other integration priority that changes is the feedback loop. Cimulate’s value compounds when the AI learns from interaction data; what queries led to purchases, what product combinations converted, what attribute combinations were searched but returned no results. That feedback loop requires an event stream from the storefront back into the data layer. In practice, this means Commerce Cloud interaction events flowing into Data Cloud, being processed as Calculated Insights, and informing the product graph over time. Most orgs don’t have this pipeline. Building it is not a small project.
What to Assess Before Cimulate Capabilities Go Live
The teams that will get value from Cimulate’s capabilities quickly are the ones that treat catalog data quality as a prerequisite, not a parallel workstream.
The assessment starts with the catalog itself. How many products have complete attribute sets? What percentage of product descriptions are structured enough to extract semantic signals from? How many catalog sources feed Commerce Cloud, and how are conflicts resolved? These questions have answers that are usually worse than teams expect. In orgs with 50,000+ SKUs across multiple catalog sources, attribute completeness rates below 60% are common. That’s the baseline the AI is working from.
The second assessment is the integration architecture. Is there a canonical product schema that all upstream sources conform to? Is catalog sync event-driven or batch? Is there a data quality gate before records reach the storefront? If the answers are no, batch, and no, the integration layer needs work before the AI layer adds value.
The third assessment is the data model in Data Cloud, if it’s already deployed. Product data in Data Cloud is often an afterthought; customer DMOs are well-defined, product DMOs are flat or absent. Extending the data model to support product relationships and semantic attributes is a schema design exercise that needs to happen before enrichment pipelines can be built.
This is the sequence: catalog data quality, then integration architecture, then semantic enrichment, then AI capability deployment. Teams that skip to the end get AI that confidently returns wrong answers.
For a structured view of how to sequence this kind of architecture work, the AI and Agentforce Architecture service page covers the assessment framework in more detail.
Key Takeaways
- The Cimulate acquisition is a data architecture event, not just a UX feature addition. Product catalog structure determines whether the AI layer can function at useful depth.
- Standard Commerce Cloud catalog models are optimized for faceted browse, not semantic retrieval. Attribute enrichment, product relationship modeling, and variant structure all need to be revisited.
- Data Cloud positioned as a product semantic layer; not just a customer data layer; is the architecture pattern that supports Cimulate’s capabilities at scale. Product Data Streams, Calculated Insights, and Data Graphs need to extend to product entities with the same rigor applied to customer profiles.
- Real-time catalog sync via Platform Events is a prerequisite. Batch pipelines introduce latency that breaks conversational commerce use cases where availability and pricing accuracy are expected.
- Catalog data quality assessment comes before AI deployment. Attribute completeness, source normalization, and canonical schema definition are the unglamorous work that determines whether the AI layer returns useful results or plausible-sounding noise.
Need help with ai & agentforce architecture?
Design and implement Salesforce Agentforce agents, Prompt Builder templates, and AI-powered automation across Sales, Service, and Experience Cloud.
Related Articles

Agentforce Operations: Architecture Guide
Agentforce Operations redefines back-office automation. Here's the architectural blueprint for deterministic agent control planes at enterprise scale.
Salesforce Prompt Builder : bonnes pratiques
Prompt Builder mal configuré = agents Agentforce imprévisibles. Les bonnes pratiques architecturales pour éviter les pièges les plus coûteux.

Salesforce AI Specialist Cert Prep 2026
The Salesforce AI Specialist certification in 2026 tests architecture judgment, not recall. Here's how to prepare for what the exam actually measures.