
The low code vs pro code Salesforce architecture debate gets framed as a skills question when it’s actually a governance question. Teams that treat it as “what can my developers do” end up with the wrong answer. The right frame is “what does this system need to remain maintainable at scale.”
This distinction matters because the cost of getting it wrong compounds. A Flow that should have been Apex becomes a 47-element spaghetti diagram that no one can debug in production. An Apex class that should have been a Flow becomes a deployment bottleneck that blocks every admin from iterating on business logic. Both failure modes are common. Both are expensive to unwind.
Why the Default Answer Is Usually Wrong
Most orgs default to one extreme. Either everything goes through Flow because “admins can maintain it,” or everything goes through Apex because “developers don’t trust the platform.” Neither position holds up architecturally.
The admin-maintainability argument for Flow breaks down past a certain complexity threshold. Flow is genuinely excellent for linear, condition-based automation with clear branching logic. It degrades badly when you need bulk-safe DML operations, complex data transformations across multiple objects, or logic that needs to be unit-tested with precision. A Flow that handles 200-record batch operations will hit governor limits in ways that are hard to predict and harder to diagnose. Apex handles bulk operations natively because you write the loop yourself and control exactly what happens inside it.
The developer-trust argument for Apex breaks down at the iteration speed end. Business rules change constantly. If every pricing adjustment, every routing rule, every SLA threshold requires a developer, a code review, a sandbox deployment, and a change set, you’ve created a system that can’t respond to the business. Flow’s value isn’t that it’s simpler. It’s that it puts the right decisions in the hands of the people closest to the business problem.
The architecture that works here is a deliberate boundary, not a preference.
Drawing the Boundary: A Decision Framework
The boundary between Flow and Apex should be drawn on three axes: complexity, volume, and ownership.
Complexity is about branching depth and data transformation requirements. If the logic requires more than three levels of conditional branching, or if it needs to reshape data structures (not just read and write fields), Apex is the right tool. Flow’s visual representation becomes a liability at high complexity, not an asset. You can’t diff a Flow in version control the way you can diff a class. Debugging a failed Flow interview in production requires reconstructing state from debug logs that weren’t designed for that purpose.
Volume is about record counts and transaction frequency. The general threshold in practice: if the automation will regularly process more than 200 records in a single transaction, or if it fires on a high-frequency object like a Platform Event or a Data Cloud activation trigger, write Apex. Flow’s bulkification is improving with each release, but it still abstracts away the control you need when governor limits are a real constraint rather than a theoretical one.
Ownership is the most underweighted axis. Who will maintain this logic in 18 months? If the answer is a Salesforce admin or a business analyst with declarative skills, Flow is correct even if a developer could write it faster in Apex today. If the answer is a developer team with a proper CI/CD pipeline, Apex gives you testability, version control, and refactoring capability that Flow cannot match.
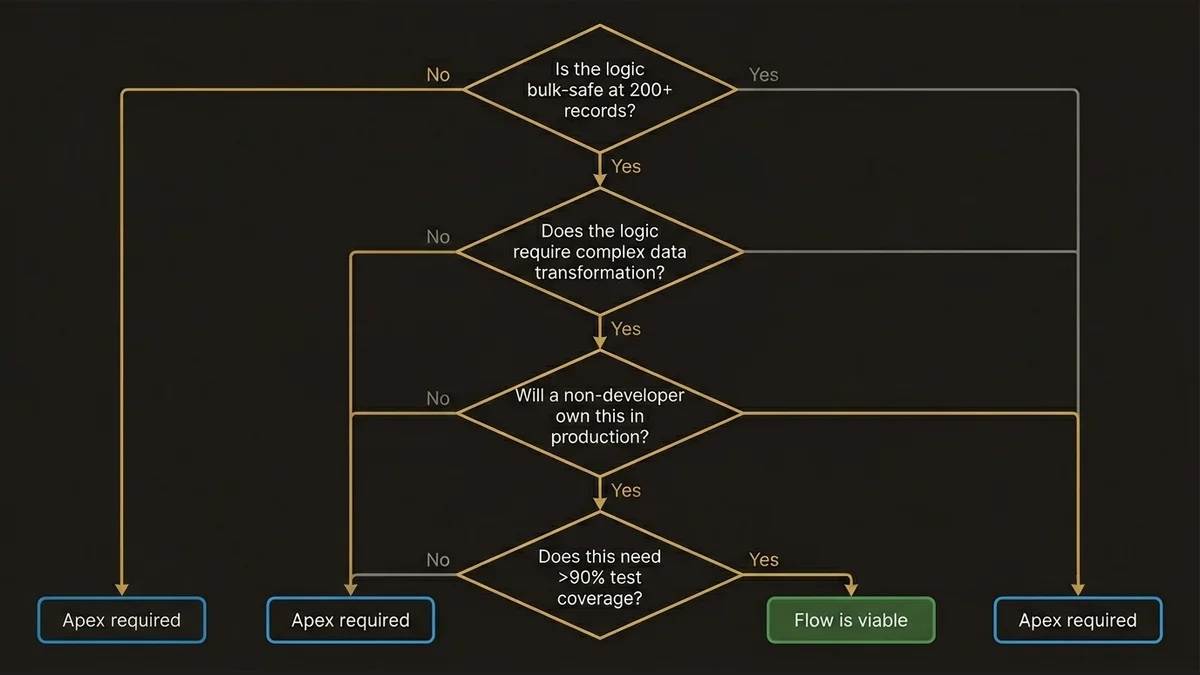
A concrete decision tree:
Is the logic bulk-safe at 200+ records?
No → Flow is viable
Yes → Apex required
Does the logic require complex data transformation?
No → Flow is viable
Yes → Apex required
Will a non-developer own this in production?
Yes → Flow preferred
No → Apex preferred
Does this need >90% test coverage with assertion-level precision?
Yes → Apex required
No → Flow is viableWhen all three axes point the same direction, the decision is easy. When they conflict, ownership usually wins, because a technically superior solution that no one can maintain is an operational liability.
Where the Real Architectural Risk Lives
The dangerous zone isn’t pure Flow or pure Apex. It’s the hybrid layer where both exist on the same object and interact in ways that aren’t documented.
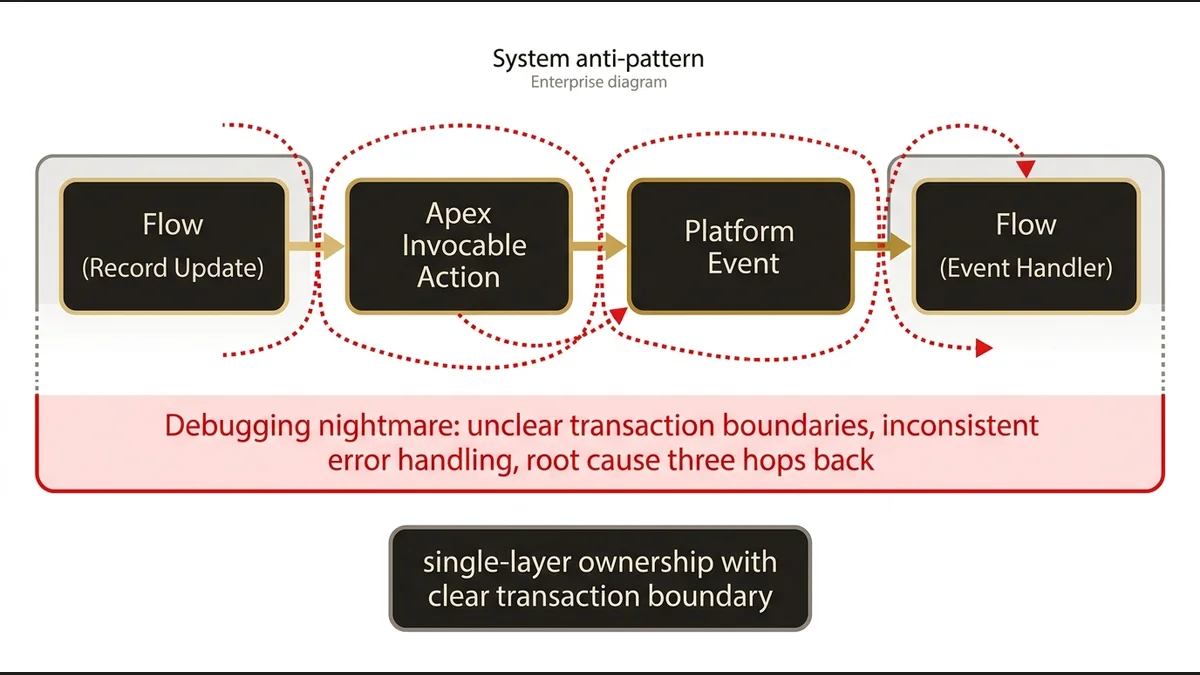
A common pattern in enterprise orgs: a Flow fires on record update, calls an Apex invocable action, which triggers a Platform Event, which fires another Flow. Each individual piece was a reasonable decision at the time. The system as a whole is a debugging nightmare. Transaction boundaries become unclear. Error handling is inconsistent. When something fails, the stack trace points to the middle of the chain and the root cause is three hops back.
The architectural principle here is transaction ownership. One layer should own the transaction for a given business process. If Apex owns it, Flow should not be injecting logic into the same record operation through a separate trigger path. If Flow owns it, Apex invocable actions should be stateless utilities, not stateful orchestrators.
This is where multi-cloud integration design patterns become relevant. The same principle that governs service boundaries in a multi-cloud architecture applies to the low code / pro code boundary inside a single org: clear ownership, explicit interfaces, no shared mutable state across layers.
The Agentforce Dimension
Spring ‘26 adds a layer to this decision that most orgs aren’t accounting for yet. Agentforce Actions can invoke Flow or Apex. The Atlas Reasoning Engine doesn’t care which one sits behind an Action. But the architectural implications differ significantly.
Flow-backed Actions are easier to iterate on. You can modify the logic without a deployment. For Actions that encode business rules likely to change (routing logic, eligibility checks, response templates), Flow gives you the iteration speed that agent development requires. Prompt Builder integrations work cleanly with Flow-backed Actions because the data shapes are predictable.
Apex-backed Actions are necessary when the Action needs to perform complex data operations, call external systems through MuleSoft or External Services, or handle error states with precision. An agent Action that queries Data Cloud Data Graphs, applies Calculated Insights, and writes back to CRM needs Apex. The data transformation requirements alone disqualify Flow.
The forward-looking implication: orgs that have invested in clean Apex service layers with well-defined interfaces will find Agentforce adoption significantly easier. The invocable action pattern maps directly to the Action model. Orgs with logic scattered across 200 Flows and undocumented Apex triggers will face a rationalization project before they can build reliable agents. The architectural decisions you make today about low code vs pro code boundaries directly determine your Agentforce readiness in 12 months.
For a deeper look at how this plays out in agent architecture specifically, the Agentforce implementation guide covers the Action design patterns in detail.
What Most Teams Get Wrong in Practice
The most common mistake is treating this as a one-time decision rather than a governance policy. Teams establish a preference early, apply it inconsistently, and end up with an org where the boundary is invisible. New developers don’t know which objects have Flow automation, which have Apex triggers, and which have both. The cognitive overhead of understanding the automation layer becomes a tax on every development cycle.
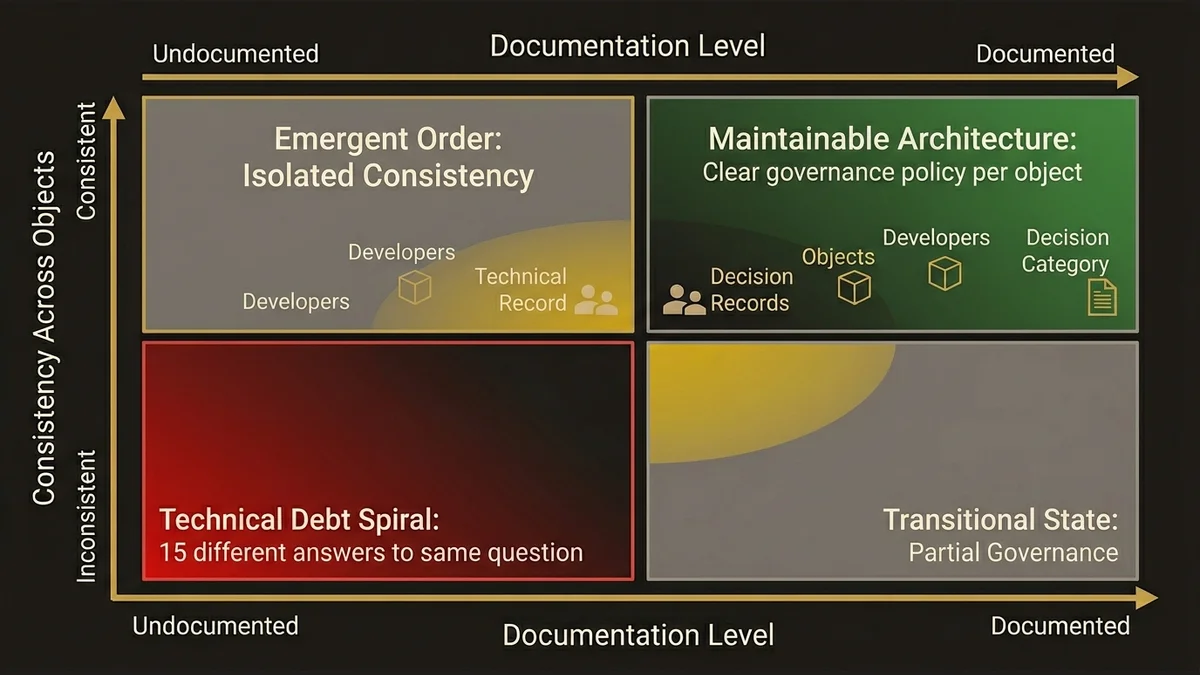
The fix is explicit documentation of the automation boundary per object, enforced through architecture review. Not a lengthy governance process, but a simple decision record: for each core object, which layer owns automation, and why. When that record exists, new automation requests have a clear starting point. When it doesn’t, every developer makes a local decision that may contradict the last one.
Orgs with 200+ consultants across 15 business units face this at scale. Without a documented boundary policy, you get 15 different answers to the same architectural question applied to the same platform. The resulting org is not unmaintainable because any individual decision was wrong. It’s unmaintainable because the decisions are inconsistent and undocumented.
If your org is already in this state, the path forward starts with an honest assessment of where the boundaries currently sit, not where they should have been. The Salesforce technical debt assessment framework provides a structured approach to that inventory.
The architectural work at /services/data-cloud-architecture regularly surfaces this problem in multi-cloud contexts, where Data Cloud activations trigger CRM automation and the ownership question becomes urgent.
Key Takeaways
- The low code vs pro code Salesforce architecture decision is a governance question, not a skills question. Draw the boundary on complexity, volume, and ownership, not developer preference.
- Flow degrades at high complexity and high volume. Apex degrades at iteration speed and ownership transfer. Neither is universally correct.
- The most dangerous architectural pattern is undocumented hybrid automation, where Flow and Apex interact on the same object without clear transaction ownership.
- Agentforce Actions can invoke either layer, but orgs with clean Apex service layers will have a structural advantage in agent adoption. The architectural decisions made today determine Agentforce readiness in 12 months.
- Document the automation boundary per object as a governance artifact. Inconsistency across that boundary is the root cause of most automation-related technical debt in mature orgs.
Need help with data 360 & multi-cloud architecture?
Unify customer data across Salesforce clouds with Data 360, build identity resolution models, and architect multi-cloud systems that actually work together.
Related Articles

Customer 360 : Patterns d'Architecture Salesforce
Les salesforce customer 360 architecture patterns qui fonctionnent vraiment en enterprise : Data Cloud, Identity Resolution, Data Graphs. Analyse techni...

Single Org vs Multi-Org : Choisir sa Stratégie
Single org vs multi-org strategie : comment choisir la bonne architecture Salesforce selon votre contexte. Critères techniques, pièges et décision frame...

Single vs Multi-Org: The Real Tradeoffs
Choosing your Salesforce org strategy shapes every integration, data model, and AI initiative for years. Here's how to make the right call architecturally.