
La plupart des projets Data Cloud échouent avant même d’avoir activé leur premier segment. Ce salesforce data cloud guide implementation existe pour corriger ça : non pas en listant des étapes génériques, mais en exposant les décisions d’architecture qui déterminent si votre projet tient à l’échelle ou s’effondre à 6 mois.
Le problème n’est pas la technologie. Le problème, c’est que les équipes traitent Data Cloud comme un outil de marketing automation alors que c’est une couche de données enterprise. Ces deux approches produisent des architectures fondamentalement différentes.
Pourquoi l’ingestion de données est la décision la plus sous-estimée
Tout commence par les Data Streams. Ce sont les pipelines d’ingestion qui alimentent Data Cloud depuis vos sources : Salesforce CRM, systèmes legacy, plateformes e-commerce, données comportementales web. La décision critique ici n’est pas “quelles données ingérer” mais “à quelle granularité et à quelle fréquence.”
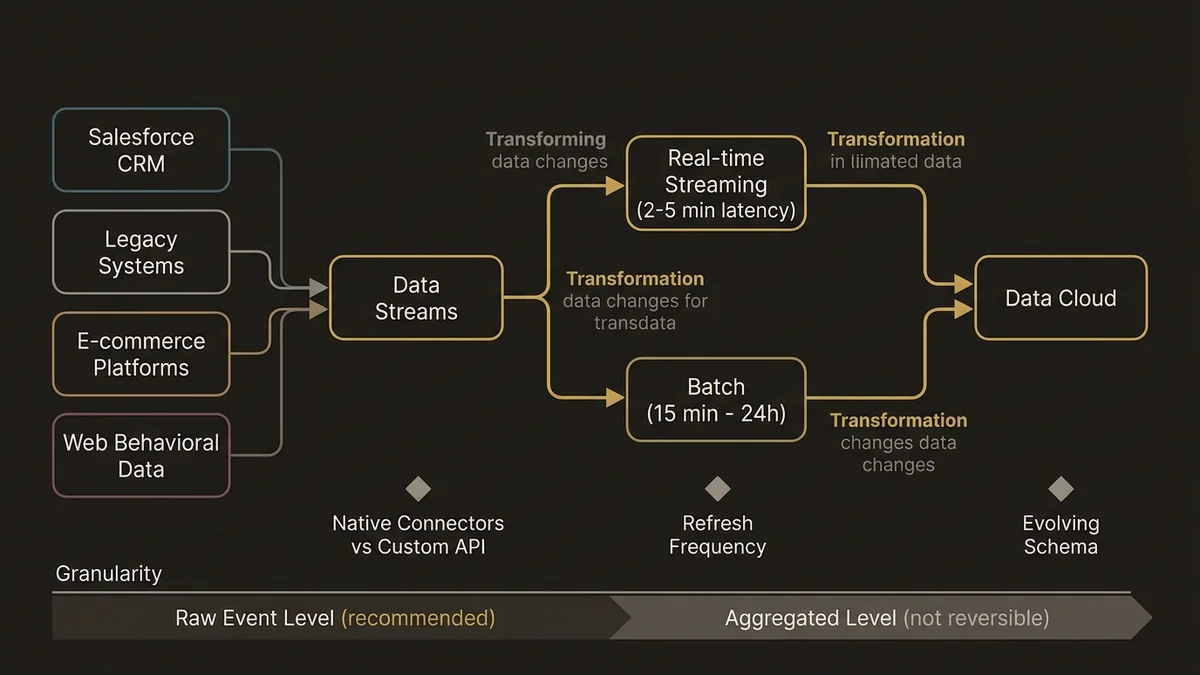
Un pattern courant dans les organisations enterprise : ingérer des données agrégées pour simplifier le modèle. Cela fonctionne jusqu’au moment où vous avez besoin de reconstruire un parcours client au niveau événement. À ce stade, vous n’avez plus les données brutes. La reconstruction est impossible sans réingestion complète.
L’architecture qui fonctionne ici est d’ingérer au niveau le plus granulaire possible dès le départ, puis d’agréger via les Calculated Insights. L’inverse n’est pas réversible sans coût significatif.
Trois points d’attention sur les Data Streams :
- Connecteurs natifs vs API custom : les connecteurs natifs Salesforce (Sales Cloud, Service Cloud, Marketing Cloud) synchronisent via des mécanismes optimisés. Les sources externes passent par des API ou des connecteurs MuleSoft. Le choix impacte la latence et la gouvernance des erreurs.
- Fréquence de refresh : les Data Streams en temps réel (streaming) ont une latence de 2 à 5 minutes pour l’activation. Les Data Streams batch ont des cycles de 15 minutes à 24 heures. Votre cas d’usage détermine lequel utiliser, pas l’inverse.
- Schéma évolutif : les champs ajoutés en aval d’un Data Stream nécessitent une remontée jusqu’à la source. Anticipez les attributs dont vous aurez besoin dans 18 mois, pas seulement aujourd’hui.
Identity Resolution : l’étape que tout le monde bâcle
C’est là que la majorité des projets accumulent une dette technique invisible. Identity Resolution est le processus qui fusionne des profils fragmentés en un Unified Individual. En pratique, c’est un ensemble de rulesets de correspondance qui s’appliquent dans un ordre défini.
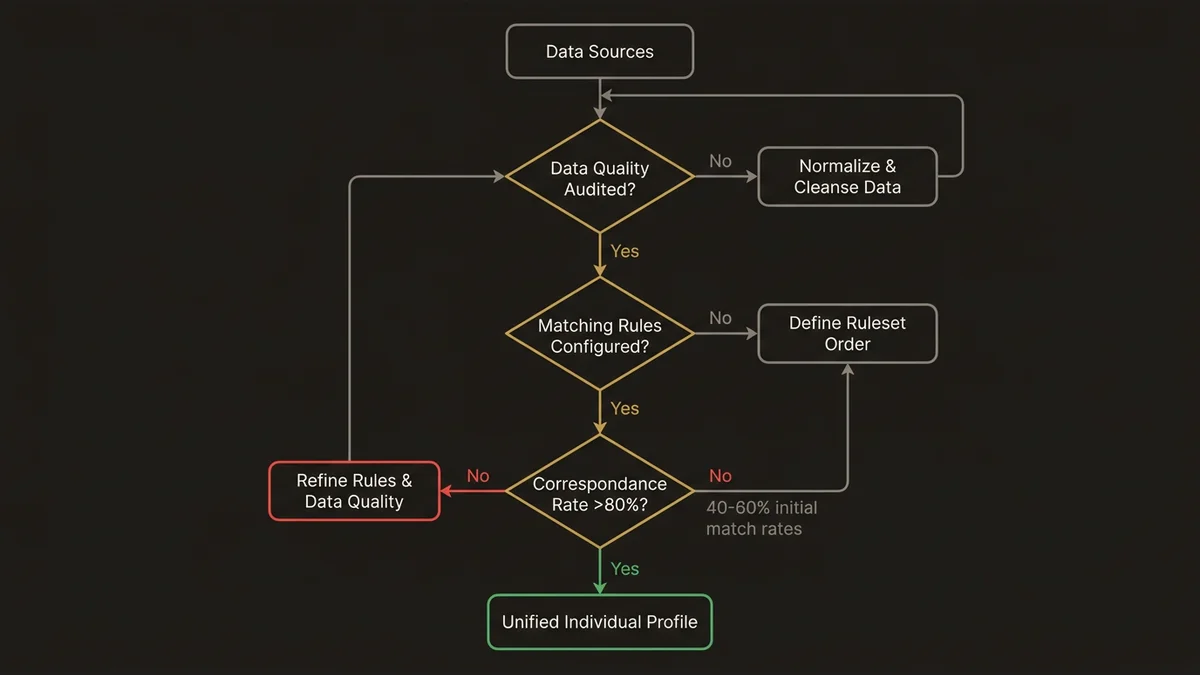
Le problème n’est pas la configuration des règles. Le problème, c’est que les équipes configurent Identity Resolution sans avoir audité la qualité de leurs données sources.
Un pattern observé à l’échelle de plus de 3 000 points de contact retail : les taux de correspondance initiaux tournent autour de 40 à 60% quand les données sources n’ont pas été normalisées. Après normalisation des emails (lowercase, suppression des espaces), des numéros de téléphone (format E.164) et des adresses, les taux montent à 75 à 85%. La différence représente des millions de profils mal unifiés ou non unifiés.
Les rulesets se configurent en cascade : correspondance exacte sur email d’abord, puis correspondance fuzzy sur nom + adresse, puis règles métier spécifiques. L’ordre compte. Une règle trop permissive en position haute crée des fusions incorrectes qui contaminent tout le modèle.
Deux décisions d’architecture à prendre avant de configurer un seul ruleset :
Première décision : quel est votre seuil de tolérance aux faux positifs ? Une fusion incorrecte de deux profils distincts est plus dommageable qu’un profil non unifié. Dans les secteurs réglementés (banque, assurance, santé), les faux positifs ont des conséquences RGPD directes. Calibrez vos règles en conséquence.
Deuxième décision : comment gérez-vous les profils anonymes ? Les visiteurs web non identifiés génèrent des Individual (anonymes) qui doivent être réconciliés avec les profils connus au moment de l’identification. Si votre architecture ne prévoit pas ce chemin de réconciliation dès le départ, vous construisez deux silos parallèles.
Data Graphs et Calculated Insights : la couche qui rend Data Cloud utilisable
Les Data Streams et Identity Resolution constituent la fondation. Les Data Graphs et Calculated Insights sont ce qui rend cette fondation exploitable par les équipes métier.
Les Data Graphs sont des vues matérialisées qui pré-calculent les jointures entre DMOs (Data Model Objects). Sans Data Graph, chaque requête de segmentation recalcule les jointures à la volée. Avec des volumes enterprise (50M+ profils, 500M+ événements), la différence de performance est d’un ordre de grandeur.
La décision d’architecture ici : quels Data Graphs créer, et pour quels cas d’usage. Un Data Graph mal conçu consomme des ressources de calcul sans apporter de valeur. Un Data Graph bien conçu réduit les temps de construction de segments de plusieurs minutes à quelques secondes.
Les Calculated Insights complètent ce dispositif. Ce sont des métriques calculées et stockées au niveau du profil : fréquence d’achat sur 90 jours, valeur vie client, score d’engagement, dernière interaction par canal. Ces métriques sont calculées une fois et réutilisées dans tous les segments qui en ont besoin, plutôt que recalculées à chaque activation.
Un pattern courant dans les organisations enterprise qui sous-utilisent Data Cloud : elles créent des segments complexes avec des calculs inline plutôt que des Calculated Insights. Les temps de construction de segments s’allongent, les équipes marketing perdent confiance dans l’outil, et le projet stagne. La correction est simple mais nécessite une refonte du modèle de données.
Les écueils d’activation qui effacent la valeur créée en amont
Vous pouvez avoir une architecture d’ingestion irréprochable, une Identity Resolution bien calibrée, des Data Graphs optimisés. L’activation peut quand même échouer.
Trois écueils récurrents :
Gouvernance des segments. Les segments Data Cloud sont des définitions d’audience dynamiques. Sans gouvernance, les équipes métier créent des centaines de segments redondants, les temps de calcul explosent, et personne ne sait plus quel segment est la source de vérité pour quelle campagne. Établissez une taxonomie et un processus de validation avant d’ouvrir l’accès en self-service.
Latence d’activation mal comprise. Data Cloud n’est pas un système temps réel au sens strict. L’activation vers Marketing Cloud, par exemple, passe par des mécanismes de synchronisation qui ajoutent de la latence. Pour les cas d’usage qui nécessitent une réaction en moins d’une minute (abandon de panier, alerte fraude), l’architecture correcte passe par Platform Events et une logique Flow, pas par un segment Data Cloud activé en batch.
Absence de boucle de feedback. Les données d’engagement (email ouvert, lien cliqué, conversion) doivent remonter dans Data Cloud pour alimenter les Calculated Insights et affiner les segments. Sans cette boucle, votre modèle de données se dégrade progressivement par rapport à la réalité comportementale. Architecturez le retour des données d’activation dès le début du projet, pas comme une phase 2.
Ce que les équipes optimisent mal en phase de démarrage
La plupart des équipes optimisent pour la vitesse de mise en production du premier cas d’usage. C’est compréhensible. C’est aussi ce qui crée la dette architecturale qui ralentit tout le reste.
L’architecture qui survit optimise pour l’extensibilité du modèle de données. Concrètement : les DMOs que vous créez aujourd’hui pour le cas d’usage e-commerce doivent pouvoir accueillir les données du programme de fidélité dans 6 mois, et les données du service client dans 12 mois, sans refonte.
Cela implique de travailler le modèle de données en amont avec les équipes métier de chaque domaine, même celles dont les données n’arrivent pas en phase 1. Une heure de modélisation partagée en amont évite trois semaines de migration de données en aval.
La décision actuelle sur le modèle de données détermine si vous pouvez ajouter de nouvelles sources en configuration ou si chaque nouvelle source nécessite une intervention d’architecture. À l’échelle d’une ETI avec 5 à 10 systèmes sources, la différence représente plusieurs mois de charge sur 3 ans.
Pour aller plus loin sur les patterns d’intégration entre Data Cloud et les systèmes legacy, l’article sur Data Cloud vs MuleSoft détaille les critères de choix entre connecteurs natifs et couche d’intégration dédiée. Et si votre organisation envisage d’activer Agentforce sur ces profils unifiés, l’architecture Identity Resolution décrite ici est un prérequis direct, comme expliqué dans le guide Agentforce pour les DSI.
Si votre projet Data Cloud est déjà en production et que vous observez des symptômes (temps de segmentation longs, taux de correspondance Identity Resolution faibles, dette de gouvernance), une évaluation de l’architecture existante est souvent plus rapide qu’une refonte. Les services d’architecture Data Cloud couvrent ce type de diagnostic.
Points clés
- Les Data Streams doivent ingérer au niveau le plus granulaire possible dès le départ. L’agrégation se fait via Calculated Insights. L’inverse nécessite une réingestion complète.
- Identity Resolution sans audit préalable de la qualité des données sources produit des taux de correspondance de 40 à 60%. Après normalisation, les taux atteignent 75 à 85%.
- Les Data Graphs pré-calculent les jointures entre DMOs. Sur des volumes de 50M+ profils, ils réduisent les temps de construction de segments d’un ordre de grandeur.
- L’activation en temps réel (sous une minute) ne passe pas par les segments Data Cloud. Elle passe par Platform Events et Flow.
- Le modèle de données initial détermine si chaque nouvelle source de données est une configuration ou un projet d’architecture. Modélisez pour les sources des 18 prochains mois, pas seulement pour le cas d’usage actuel.
