

Most Salesforce org health checks produce a PDF nobody reads. They catalog automation counts, API usage percentages, and storage metrics; then get filed next to the last three assessments that said the same things. The real risks stay buried.
A proper salesforce org health check assessment guide starts from a different premise: you’re not auditing a platform, you’re stress-testing an architecture. The difference determines whether your findings drive decisions or collect dust.
What Most Health Checks Get Wrong
The standard approach treats org health as a compliance exercise. Count the Flows, flag the inactive ones, note the governor limit proximity, recommend a cleanup sprint. Done. This misses the structural problems that compound over time and eventually force a crisis migration or a distressed recovery project.
Three categories of risk are chronically underweighted:
Coupling density is the first. An org can have 200 Flows and be perfectly maintainable, or it can have 40 Flows so deeply entangled with Apex triggers and Platform Events that a single field rename cascades into a three-week regression cycle. The number is irrelevant. The dependency graph is what matters.
Data model drift is the second. Orgs accumulate custom objects and fields that were built to solve problems that no longer exist. The danger isn’t the storage cost; it’s that these orphaned structures get referenced in reports, Flows, and integrations that nobody fully understands. When a migration or Data Cloud implementation lands on top of this, the mapping exercise becomes exponentially harder. Orgs running 3,000+ custom fields without a documented data dictionary are not unusual in enterprise contexts; they’re the norm.
Governance erosion is the third. This is the hardest to quantify and the most predictive of future failure. When you find 15 System Administrator profiles with full modify-all access, or Apex classes deployed directly to production without a change management process, you’re not looking at a security problem. You’re looking at an org where the architectural guardrails have been removed, and every subsequent change carries compounding risk.
The Assessment Framework That Actually Works
A credible org health assessment runs across four dimensions, in this order.
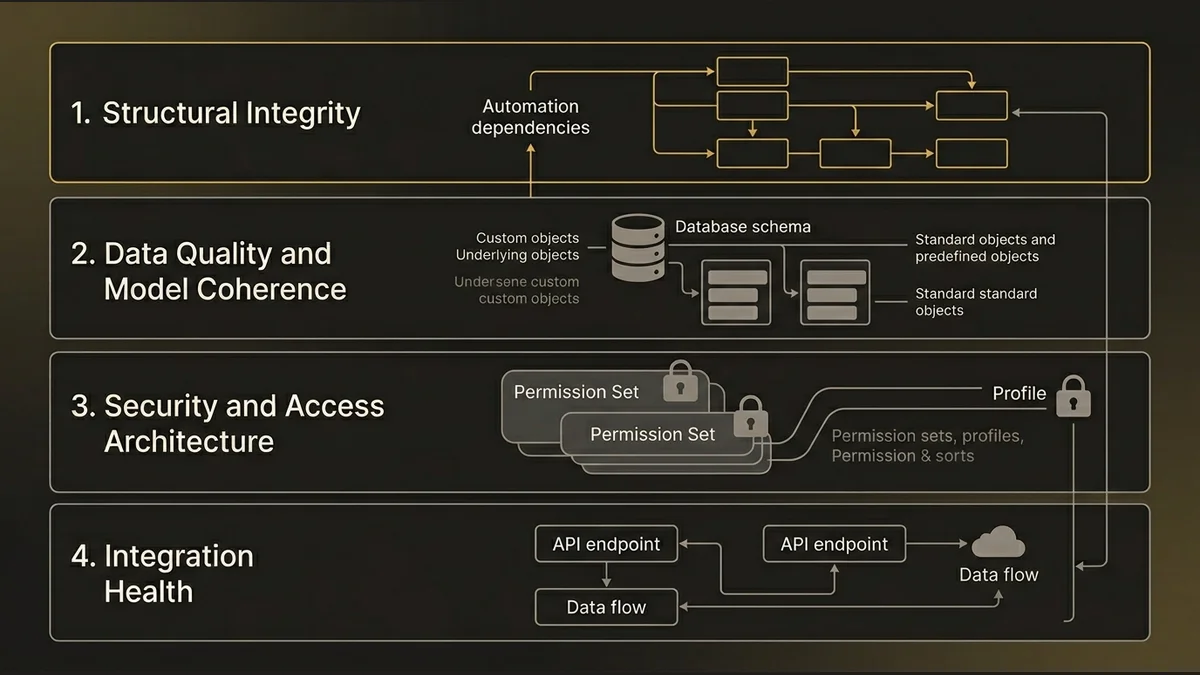
Structural integrity comes first. This means mapping the automation layer, not just inventorying it. For every Flow, trigger, and process, you need to understand what it reads, what it writes, and what it calls. The Setup dependency viewer (the “Where Is This Used” surface in Setup) gets you partway there, but for complex orgs you need to trace cross-object relationships manually or with a metadata analysis tool. The output should be a dependency map, not a list.
Data quality and model coherence comes second. Pull the full custom object and field inventory. Cross-reference against actual usage data from CRM Analytics or a metadata query. Fields with zero population across more than 10,000 records and no Flow or Apex reference are candidates for deprecation. More importantly, look for objects that duplicate standard Salesforce objects, a custom “Contract” object sitting alongside the standard Contract object, for example, because these represent architectural decisions that will create friction in every future implementation.
Security and access architecture comes third. Profile and permission set sprawl is the most common finding in enterprise orgs. The pattern that signals real risk isn’t just over-permissioned profiles; it’s permission sets that were created as one-off fixes and never reviewed, layered on top of profiles that were never cleaned up. The cumulative effect is an access model that nobody can fully describe, which means nobody can confidently change it.
Integration health comes fourth. Map every inbound and outbound API integration. For each one, document the authentication method, the data volume, the error handling behavior, and the owner. In practice, orgs that have been running for five or more years typically have three to five integrations where the original developer has left, the documentation doesn’t exist, and the integration is running on a named user credential that belongs to someone who may no longer be with the organization. These are ticking clocks.
For a more detailed look at how technical debt compounds across these dimensions, the Salesforce technical debt assessment framework covers the scoring methodology in depth.
How to Prioritize What You Find
Every health assessment produces more findings than any team can address in a reasonable timeframe. The prioritization mistake is treating severity as the primary sort key. A critical security misconfiguration that affects a non-production integration is less urgent than a medium-severity automation conflict that fires on every Opportunity close.
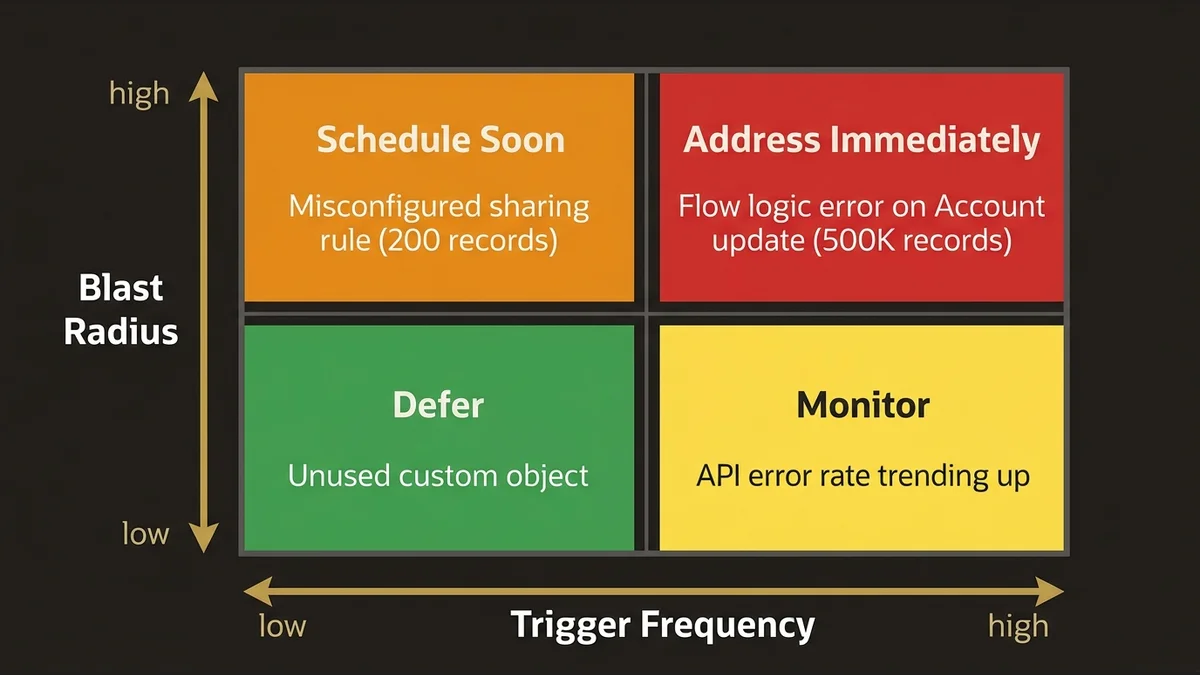
The framework that works is a two-axis matrix: blast radius against trigger frequency. Blast radius is how many records, users, or downstream systems are affected when this issue manifests. Trigger frequency is how often the conditions for that issue occur.
A Flow with a logic error that runs on every Account update in a 500,000-record org has a high trigger frequency and potentially enormous blast radius. It goes to the top of the list regardless of how it scores on a traditional severity scale. A misconfigured sharing rule on a rarely-used custom object with 200 records scores low on both axes and can wait.
This reframing also changes the conversation with business stakeholders. Instead of presenting a list of technical problems, you’re presenting a risk-weighted roadmap with clear business impact language. “This automation conflict has fired incorrectly on 12,000 Opportunity records in the last 90 days” lands differently than “we found a Flow error.”
The Metrics That Predict Future Failure
Certain org metrics are lagging indicators; they tell you what already went wrong. Others are leading indicators; they tell you what’s about to go wrong. Most health checks focus on lagging indicators because they’re easier to measure.
The leading indicators worth tracking:
Apex test coverage trending downward over six months means developers are shipping code faster than they’re writing tests. This is a governance signal, not a technical one. The coverage number itself matters less than the direction.
Flow version proliferation; specifically, the ratio of active Flow versions to total Flow versions; indicates whether the team is iterating cleanly or accumulating dead versions that create confusion during debugging. An org with 300 total Flow versions and 40 active ones has a different health profile than one with 300 total and 280 active.
API error rate trends on named integrations. A 2% error rate that was 0.5% six months ago is a more urgent signal than a stable 5% error rate. The trend indicates something changed; either in the org or in the external system; and nobody noticed.
Permission set assignment growth rate. If the number of permission set assignments is growing faster than the user count, the access model is drifting. This compounds until a security review forces a painful remediation.
Turning Assessment Findings Into an Architectural Roadmap
The deliverable from a health check should not be a findings report. It should be a phased remediation architecture with clear sequencing logic.
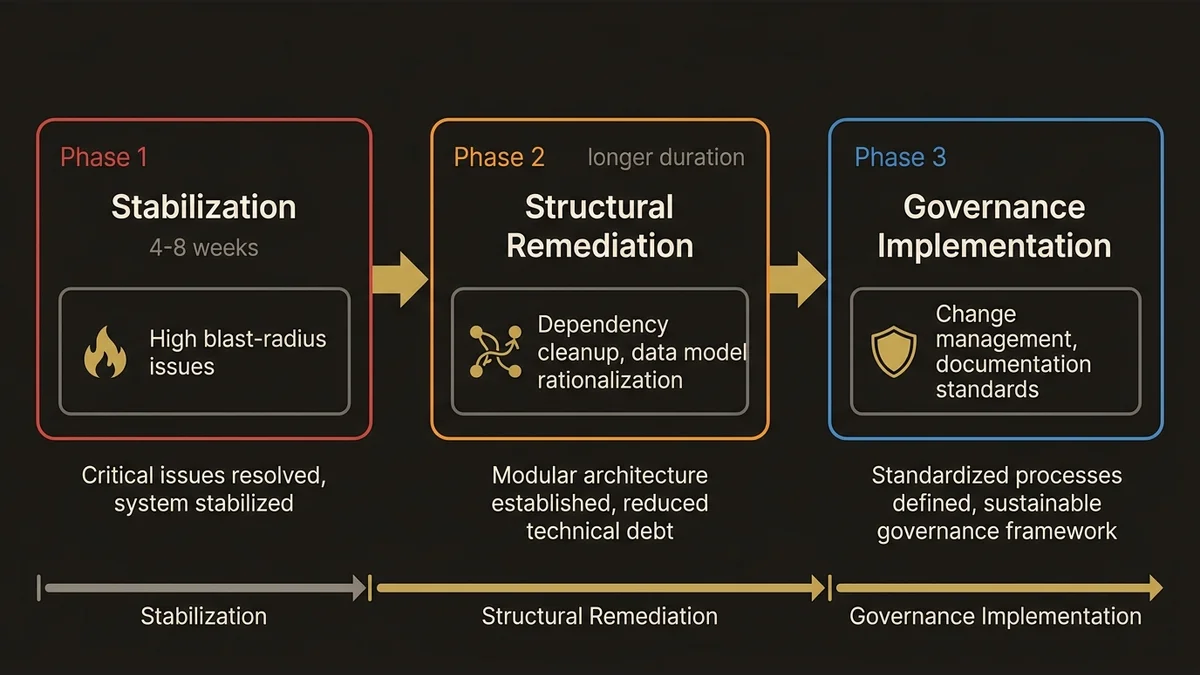
Phase one is always stabilization: address the high blast-radius, high-frequency issues that are actively causing data or process problems. This is typically a four-to-eight week effort and produces immediate, demonstrable value.
Phase two is structural remediation: clean up the dependency tangles, deprecate the orphaned data model elements, and rationalize the permission architecture. This is the work that makes future development faster and safer. It’s also the work that gets deprioritized when there’s no architectural oversight, because it doesn’t produce visible features.
Phase three is governance implementation: establish the change management processes, metadata documentation standards, and architectural review gates that prevent the org from returning to its current state. Without this phase, you’re on a two-to-three year cycle back to the same assessment.
The sequencing matters because phase three work done before phase two is wasted; you’re governing a broken architecture. And phase two work done before phase one is dangerous; you’re refactoring while active fires are burning.
When the remediation scope outgrows a standard project, the org health recovery service covers the architectural approach for distressed org situations specifically. (See also the complementary architecture review checklist for the structural integrity dimension.)
Key Takeaways
- The dependency graph is the deliverable. An inventory of Flows and triggers without it cannot drive remediation.
- Data model drift and governance erosion predict future failure better than storage metrics or governor limits. They are also the dimensions standard assessments most consistently underweight.
- Sort findings by blast radius times trigger frequency. Severity scales mislead because severity ignores how often the conditions actually occur.
- Track leading indicators (test coverage trend, Flow version ratio, API error rate trend, permission set growth rate). Lagging indicators only confirm what already broke.
- An assessment without phased remediation architecture is an audit, not an assessment. Stabilization first; structural remediation second; governance third. Skip the sequence and you waste the work.
