The Momentum acquisition looks clean on a slide deck. In practice, the Salesforce Momentum API integration architecture problem is a data model collision waiting to happen. Conversation intelligence platforms were never designed to fit neatly into CRM schemas, and Momentum is no exception.
This matters because the value of Momentum isn’t in the audio files. It’s in the structured signals extracted from those conversations: deal risks, competitor mentions, next steps, sentiment shifts. Getting those signals into Salesforce in a way that’s actually queryable, actionable, and trustworthy requires architectural decisions that most orgs will get wrong in the first pass.
Why Conversation Data Doesn’t Map Cleanly to Salesforce Objects
Salesforce’s core data model is transactional and relational. Opportunities have stages. Contacts have roles. Activities have types. Everything resolves to a record with a clear owner and a clear relationship to another record.
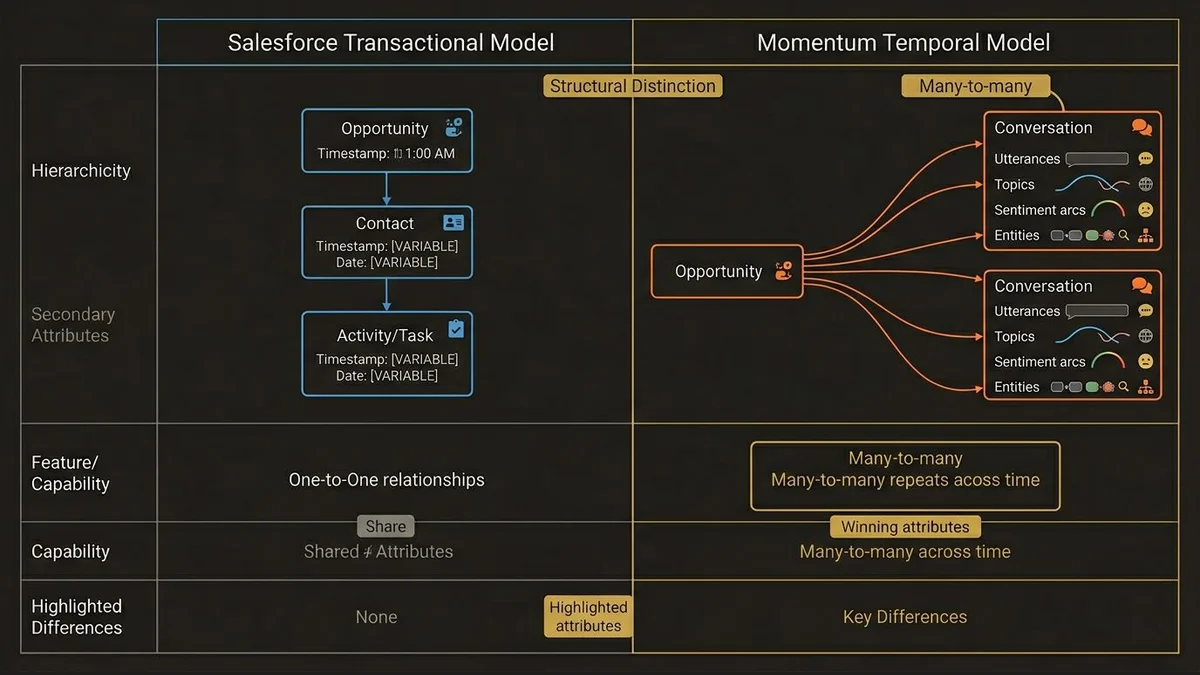
Momentum’s data model is temporal and contextual. A conversation isn’t a single event with a timestamp. It’s a sequence of utterances, topics, sentiment arcs, and extracted entities that span minutes or hours. The relationship between a conversation and a deal isn’t one-to-one. A single Opportunity might have 40 calls across 12 contacts over 6 months, each call producing dozens of discrete signals.
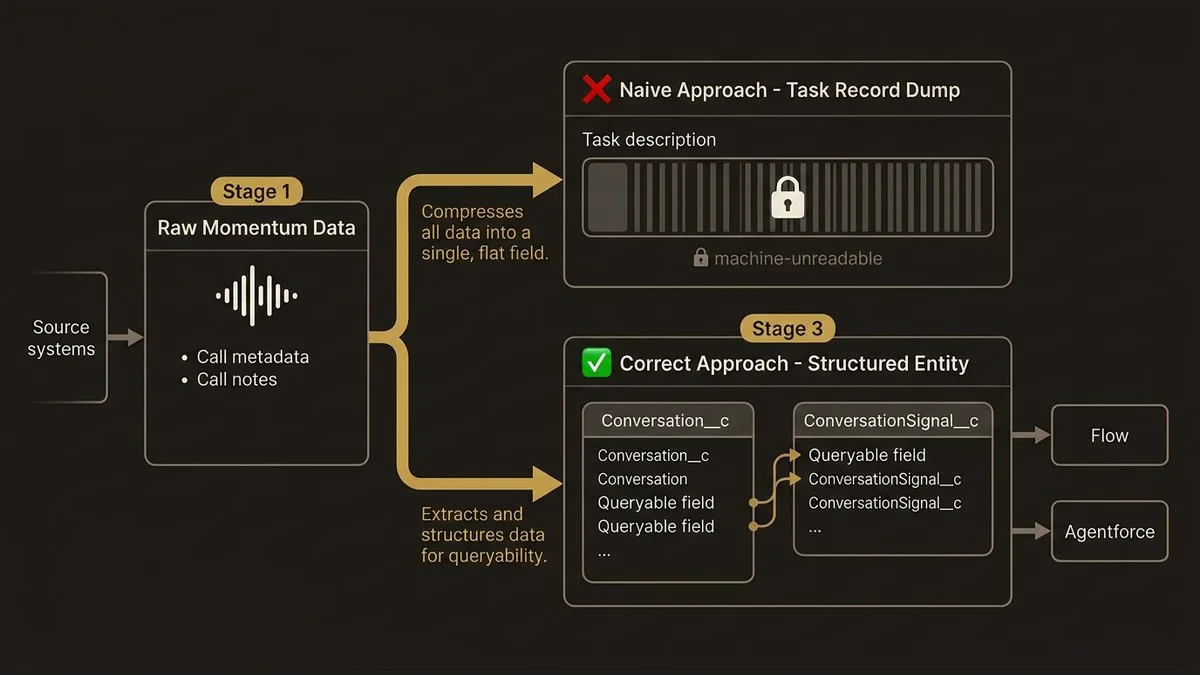
The naive mapping approach is to push Momentum call summaries into Task records. This is what most orgs default to because it’s fast and requires no schema changes. It’s also architecturally wrong. Task records are flat. They have a subject, a description, and a few standard fields. Dumping a call summary into the description field makes the data human-readable but machine-useless. You can’t segment on it, you can’t aggregate it, and you can’t feed it reliably into Agentforce actions without brittle text parsing.
The correct approach is to treat conversation data as a first-class data entity, which means either extending the Salesforce schema with custom objects or routing the data through Data Cloud where it can be modeled properly.
The Custom Object vs. Data Cloud Decision
This is the architectural fork that determines everything downstream.
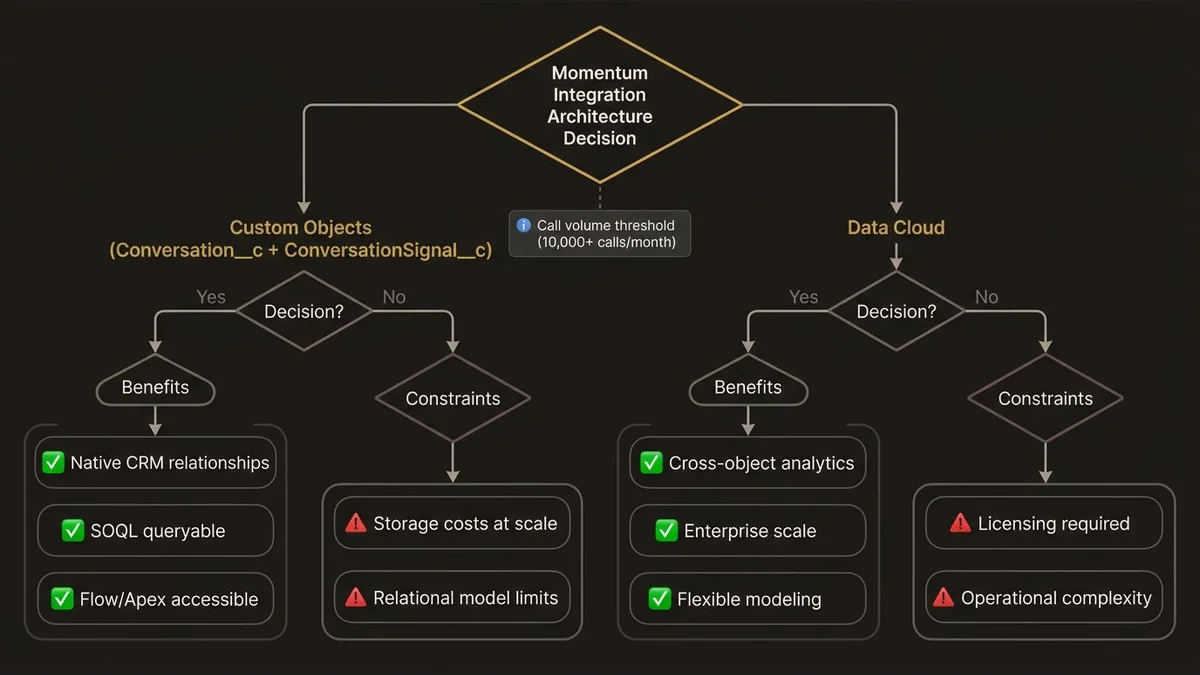
Custom objects in Salesforce give you native CRM relationships, standard security model, and direct accessibility from Flow, Apex, and Agentforce actions. A Conversation__c object with child ConversationSignal__c records is queryable via SOQL, reportable in CRM Analytics, and can trigger automation without additional infrastructure. For orgs that don’t have Data Cloud licensed or aren’t ready to operationalize it, this is the pragmatic path.
The problem is scale and flexibility. Enterprise orgs running 10,000+ calls per month will generate millions of signal records within a year. Custom object storage costs accumulate. More importantly, the relational model breaks down when you need cross-object analytics. Answering “which conversation topics correlate with deals that slip past close date” requires joining Conversation signals to Opportunity history to Activity timelines. In native Salesforce, that query becomes a reporting nightmare.
Data Cloud handles this better. Momentum call data ingested via Data Streams can be modeled as a custom Data Model Object, related to the Unified Individual through Identity Resolution, and joined to Opportunity data through a Data Graph. Calculated Insights can then surface pre-computed metrics like “average competitor mentions per deal stage” directly on the Unified Profile. That’s the architecture that makes Momentum data genuinely useful for Agentforce reasoning, not just human review.
The decision rule: if your org has Data Cloud licensed and your use case involves AI-driven activation (Agentforce agents using conversation signals to prioritize outreach, generate follow-up content, or flag at-risk deals), go Data Cloud. If you’re primarily solving for rep coaching and manager visibility, custom objects with a well-designed schema will serve you adequately and ship faster.
For a deeper look at how Data Cloud’s identity layer handles the matching problem across conversation participants and CRM contacts, the Data Cloud identity resolution architecture article covers the ruleset design in detail.
Where the API Integration Actually Breaks
Momentum exposes conversation data via webhook and REST API. The integration pattern most teams reach for is a direct API-to-Salesforce push using MuleSoft or a lightweight middleware layer. This works in development. It degrades in production for three reasons.
First, conversation processing isn’t synchronous. Momentum’s AI analysis pipeline runs after the call ends, not during it. Depending on call length and queue depth, enriched data can arrive anywhere from 5 minutes to 2 hours post-call. Any integration that assumes near-real-time availability of structured signals will produce incomplete records if it fires too early.
The fix is event-driven ingestion. Momentum’s webhook fires when processing completes, not when the call ends. Your integration layer should listen for the call.processed event, not call.ended. This sounds obvious but is consistently missed in initial implementations because developers test with short calls that process quickly.
Second, participant matching is unreliable without a resolution layer. Momentum identifies call participants by email address or phone number. Salesforce Contacts and Leads have email and phone fields, but they’re not deduplicated. An enterprise org with 8M+ records across multiple business units will have the same prospect appearing as 3 Leads and 1 Contact across different divisions. When Momentum pushes a call record, which record does it attach to? Without an explicit resolution strategy, you get either duplicate associations or silent failures where the call lands on the wrong record.
This is where Identity Resolution in Data Cloud earns its cost. Matching rulesets that normalize email domains, resolve phone number formats, and apply fuzzy name matching against the Unified Individual give you a reliable anchor point for conversation data. Without it, you’re building on a foundation that will produce data quality complaints within 90 days of go-live.
Third, the signal taxonomy needs governance before the integration goes live. Momentum extracts entities like competitor mentions, pricing objections, and next steps. But the category labels Momentum uses won’t match your internal taxonomy. “Pricing concern” in Momentum might map to three different objection types in your sales methodology. If you ingest raw Momentum labels without a mapping layer, you’ll end up with a signal dataset that’s inconsistent and can’t be used for reliable segmentation or Agentforce grounding.
The architecture that works here is a transformation layer between Momentum’s API output and your Salesforce data model. MuleSoft DataWeave is the right tool for this if you’re already in the MuleSoft ecosystem. The transformation maps Momentum’s signal categories to your internal taxonomy, normalizes participant identifiers before the resolution step, and handles the async timing by queuing events until the call.processed webhook fires.
Agentforce Grounding: What the Data Model Has to Support
If the end goal is Agentforce agents that can reason over conversation history, the data model requirements are more demanding than what’s needed for reporting alone.
The Atlas Reasoning Engine retrieves context through grounding, which means it needs to query structured data at inference time. For conversation signals to be useful to an Agentforce agent, they need to be accessible via a Data Graph or a Prompt Builder template that can retrieve relevant signals for a given Opportunity or Contact.
This has direct implications for how you model the data. Signals need to be associated to the Opportunity, not just to the call. A call might involve three Contacts and touch two Opportunities. The signal “competitor X mentioned” needs to be resolvable to the right Opportunity context, not just stored as a property of the call record.
The data model that supports Agentforce grounding looks like this: a ConversationEvent DMO in Data Cloud, related to UnifiedIndividual via participant matching, related to SalesOrder or Opportunity via a deal association DMO, with Calculated Insights that aggregate signal counts and recency at the Opportunity level. The Data Graph pre-joins these relationships so the Atlas Reasoning Engine can retrieve “last 5 calls on this deal, top 3 signals per call” without running expensive joins at inference time.
Getting this right at the data model stage is significantly cheaper than retrofitting it after Agentforce is deployed. The Agentforce agent design patterns for enterprise article covers how grounding architecture affects agent reliability in production.
For orgs planning to build this out properly, the architectural decisions around Data Cloud modeling and Agentforce integration are covered in detail at /services/data-cloud-architecture.
Key Takeaways
- Task records are the wrong target for Momentum data. Flat activity records make conversation signals human-readable but machine-useless. Custom objects or Data Cloud DMOs are the correct modeling targets depending on your activation use case.
- Event timing matters more than most teams expect. Integrate against Momentum’s
call.processedwebhook, notcall.ended. Enriched signal data is not available synchronously after a call completes. - Participant matching without a resolution layer produces data quality failures within 90 days. Identity Resolution in Data Cloud, or an explicit deduplication step in your MuleSoft transformation, is non-negotiable at enterprise scale.
- Signal taxonomy governance must precede integration build. Mapping Momentum’s category labels to your internal sales methodology taxonomy is a business decision that can’t be delegated to the integration developer.
- Agentforce grounding requires Opportunity-level signal aggregation, not just call-level storage. Data Graphs with pre-computed Calculated Insights are the architecture that makes conversation signals usable by the Atlas Reasoning Engine at inference time without prohibitive latency.
Need help with ai & agentforce architecture?
Design and implement Salesforce Agentforce agents, Prompt Builder templates, and AI-powered automation across Sales, Service, and Experience Cloud.
Related Articles

Agentforce Operations: Architecture Guide
Agentforce Operations redefines back-office automation. Here's the architectural blueprint for deterministic agent control planes at enterprise scale.
Salesforce Prompt Builder : bonnes pratiques
Prompt Builder mal configuré = agents Agentforce imprévisibles. Les bonnes pratiques architecturales pour éviter les pièges les plus coûteux.

Salesforce AI Specialist Cert Prep 2026
The Salesforce AI Specialist certification in 2026 tests architecture judgment, not recall. Here's how to prepare for what the exam actually measures.