La segmentation d’audience dans Data Cloud est vendue comme une capacité clé de la plateforme. En pratique, la majorité des organisations enterprise qui l’activent obtiennent des segments inexacts, des délais d’activation trop longs, ou les deux. Le problème n’est pas la fonctionnalité; c’est l’architecture qui la précède.
Pourquoi la segmentation échoue avant même d’être configurée
La data cloud segmentation audience Salesforce repose sur une hypothèse fondamentale : vos données sont unifiées avant d’être segmentées. Cette hypothèse est fausse dans la quasi-totalité des implémentations initiales.
Le schéma classique : une organisation ingère ses Data Streams (CRM, e-commerce, ERP, données comportementales web), configure quelques règles d’Identity Resolution, et passe directement à la création de segments. Le résultat est prévisible; des profils dupliqués, des attributs manquants, des Calculated Insights calculés sur des données partielles. Un segment “clients VIP actifs” peut contenir 40% de doublons si les rulesets d’Identity Resolution ne couvrent pas les cas de correspondance email/téléphone croisés.
L’Identity Resolution dans Data Cloud n’est pas un processus binaire. Les rulesets de correspondance produisent des Unified Individuals avec des scores de confiance variables. Segmenter sans comprendre la distribution de ces scores, c’est construire sur du sable. Dans les organisations avec plus de 3 000 points de contact retail, il n’est pas rare que 15 à 25% des profils unifiés présentent des ambiguïtés de correspondance qui affectent directement la qualité des segments downstream.
L’architecture qui fonctionne : Data Graphs avant Segments
La bonne séquence architecturale est contre-intuitive pour les équipes habituées aux CDP traditionnels.
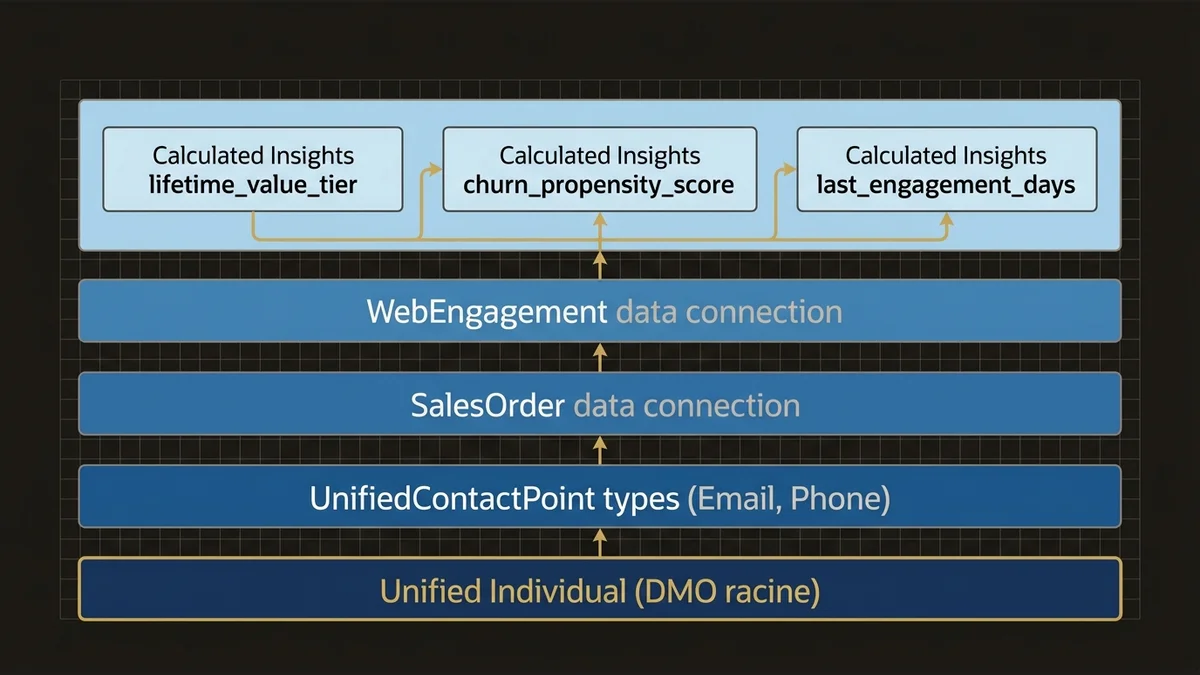
Avant de créer le moindre segment, l’investissement doit aller dans les Data Graphs. Ces vues matérialisées pré-calculent les jointures entre Data Model Objects (DMOs); c’est ce qui rend les requêtes de segmentation performantes à l’échelle. Sans Data Graphs correctement configurés, chaque évaluation de segment déclenche des jointures à la volée sur des volumes potentiellement massifs. Le résultat : des temps de calcul de segments qui passent de quelques minutes à plusieurs heures, rendant l’activation en temps réel impossible.
La structure recommandée pour un cas d’usage retail ou telco :
Unified Individual (DMO racine)
└── UnifiedContactPointEmail
└── UnifiedContactPointPhone
└── SalesOrder (via Data Graph)
└── WebEngagement (via Data Graph)
└── Calculated Insights
├── lifetime_value_tier
├── churn_propensity_score
└── last_engagement_daysLes Calculated Insights méritent une attention particulière. Ils ne sont pas de simples champs calculés; ce sont des métriques agrégées persistées au niveau du profil unifié. Un churn_propensity_score calculé en amont d’un segment permet de créer une condition de segmentation simple (churn_propensity_score > 0.7) plutôt qu’une requête complexe sur l’historique transactionnel complet. La différence de performance est d’un ordre de grandeur.
Pour aller plus loin sur la construction de ces fondations, l’article sur l’architecture d’Identity Resolution dans Data Cloud détaille les rulesets de correspondance qui conditionnent la qualité des profils unifiés.
Les trois erreurs de configuration les plus coûteuses
Segments sans date d’expiration des membres. Par défaut, un profil entre dans un segment et n’en sort que si la condition de sortie est explicitement définie. Dans un contexte d’activation marketing, cela produit des audiences qui grossissent indéfiniment. Un segment “prospects chauds” sans condition de sortie basée sur la conversion ou l’inactivité devient rapidement un fourre-tout inutilisable.
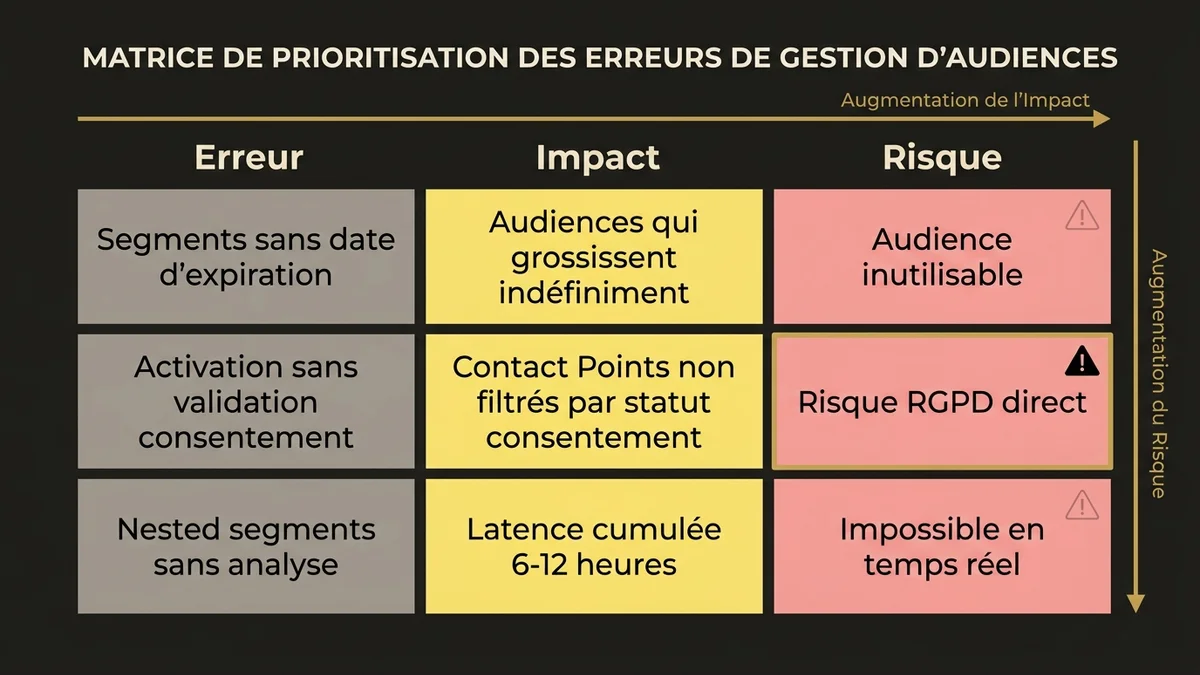
Activation directe vers les canaux sans validation de consentement. Data Cloud gère le consentement via les Contact Point Consent DMOs, mais ces objets doivent être alimentés et maintenus. L’erreur fréquente est de créer des segments sur des Unified Individuals sans vérifier que les Contact Points associés ont un statut de consentement valide pour le canal cible. En contexte RGPD, activer un segment email sans filtrage sur le consentement email expose l’organisation à un risque réglementaire direct; pas seulement théorique.
Nested segments sans analyse d’impact. Data Cloud permet de créer des segments basés sur d’autres segments (nested segmentation). C’est puissant, mais chaque niveau de nesting ajoute une dépendance de calcul. Un segment de niveau 3 qui dépend de deux segments intermédiaires peut avoir un délai de fraîcheur cumulé de 6 à 12 heures selon la fréquence de recalcul configurée. Pour les cas d’usage qui nécessitent une activation en temps réel (abandon de panier, alerte service), cette latence est rédhibitoire.
Activation : où la segmentation rencontre l’architecture système
La segmentation n’a de valeur que si l’activation est fiable. Dans Data Cloud, l’activation vers les canaux externes passe par les Activation Targets; des connecteurs configurés vers Marketing Cloud, les plateformes publicitaires, ou des systèmes tiers via API.
Le point d’attention critique : la fréquence d’activation n’est pas la même que la fréquence de recalcul des segments. Un segment recalculé toutes les 12 heures mais activé toutes les 24 heures crée une fenêtre de désynchronisation. Pour les campagnes sensibles au timing, cette désynchronisation doit être explicitement modélisée dans l’architecture.
Pour les cas d’usage Agentforce; où un agent doit prendre une décision basée sur l’appartenance d’un profil à un segment; la latence typique entre l’événement déclencheur et la disponibilité du segment mis à jour est de 2 à 5 minutes en configuration optimale (Data Streams en streaming, Calculated Insights en temps réel, segment en mode continu). Cette fenêtre est acceptable pour la plupart des interactions de service, mais doit être documentée explicitement dans les spécifications fonctionnelles.
L’intégration entre la segmentation Data Cloud et les décisions Agentforce est un sujet architectural à part entière, couvert dans le cadre des services d’architecture Data Cloud.
Gouvernance des segments à l’échelle enterprise
Dans les organisations avec plusieurs business units ou marchés géographiques, la gouvernance des segments devient un problème organisationnel autant que technique.
Un pattern qui fonctionne en pratique : distinguer les segments “fondamentaux” (calculés centralement, partagés entre BUs) des segments “opérationnels” (créés par les équipes métier pour des campagnes spécifiques). Les segments fondamentaux; lifecycle stage, valeur client, propension à l’achat; sont maintenus par l’équipe data centrale avec des SLAs de fraîcheur définis. Les segments opérationnels sont créés en self-service par les équipes marketing, mais uniquement à partir des Calculated Insights et des segments fondamentaux, jamais directement sur les DMOs bruts.
Cette séparation a deux avantages concrets. Elle protège la performance de la plateforme en évitant la prolifération de requêtes complexes sur les données brutes. Et elle garantit une cohérence sémantique; “client actif” signifie la même chose dans tous les segments opérationnels parce qu’il est défini une seule fois au niveau fondamental.
La documentation des segments est systématiquement sous-investie. Dans les organisations avec plus de 200 segments actifs, l’absence de documentation sur la logique métier, les dépendances et les propriétaires produit une dette technique invisible qui se manifeste lors des migrations ou des audits RGPD (droit à l’effacement, traçabilité des traitements).
Points Clés
- La qualité des segments Data Cloud est directement conditionnée par la maturité des rulesets d’Identity Resolution; segmenter sur des profils mal unifiés produit des audiences inexactes indépendamment de la logique de segmentation.
- Les Data Graphs sont un prérequis de performance, pas une optimisation optionnelle : sans jointures pré-calculées, les segments complexes sur des volumes enterprise dépassent systématiquement les fenêtres d’activation acceptables.
- Les Calculated Insights doivent être définis avant les segments, pas après; ils transforment des requêtes analytiques complexes en conditions de segmentation simples et performantes.
- La latence d’activation en configuration optimale (streaming + temps réel) est de 2 à 5 minutes ; tout cas d’usage nécessitant une réponse plus rapide doit être traité par Platform Events, pas par la segmentation.
- La gouvernance à deux niveaux (segments fondamentaux centralisés + segments opérationnels en self-service) est le seul pattern qui tient à l’échelle dans les organisations multi-BU sans dégrader les performances de la plateforme.
Besoin d'aide avec architecture data 360 & multi-cloud ?
Unifiez vos données client à travers les clouds Salesforce avec Data 360, construisez des modèles de résolution d'identité et architecturez des systèmes multi-cloud qui fonctionnent ensemble.
Articles connexes

Salesforce Data Cloud Identity Resolution
Identity Resolution dans Data Cloud : architecture, rulesets et pièges à éviter pour unifier vos profils clients à l'échelle enterprise.
Salesforce Data Cloud : guide d'implémentation
Les erreurs d'architecture qui font échouer les projets Data Cloud en enterprise. Patterns concrets pour une implémentation qui tient à l'échelle.