
Most candidates approaching the Salesforce Data Cloud consultant certification guide their preparation around feature memorization. That approach fails at the exam and, more importantly, fails in production. The certification tests architectural judgment, not documentation recall.
This is worth taking seriously. Data Cloud is the connective tissue for every Agentforce deployment, every real-time segmentation use case, and every Customer 360 initiative in the Salesforce ecosystem. Getting the architecture wrong costs organizations months of remediation work.
What the Exam Actually Tests
The official exam outline lists topics like Data Streams, Identity Resolution, and Calculated Insights. What it doesn’t advertise is that the hard questions are all about tradeoffs and sequencing, not definitions.
A representative hard question pattern: given a scenario with three ingestion sources, conflicting identity signals, and a latency requirement, which Identity Resolution ruleset configuration produces a Unified Individual without over-merging? That question requires understanding how fuzzy match rules interact with deterministic rules, what happens when a contact appears in both CRM and a web analytics stream with different email formats, and why over-merging is architecturally worse than under-merging in most enterprise contexts.
The exam weights break down roughly as follows across the major domains:
- Data ingestion and modeling (Data Streams, DMO mapping, schema normalization)
- Identity Resolution (ruleset design, match rules, reconciliation)
- Segmentation and activation (Segment definitions, activation targets, refresh cadence)
- Calculated Insights and Data Graphs (pre-computed metrics, materialized join patterns)
- Agentforce and AI integration (grounding, real-time profile access)
The last domain has grown significantly in recent exam versions. Expect questions about how Data Cloud feeds the Atlas Reasoning Engine and what latency characteristics are realistic for real-time agent grounding.
Identity Resolution Is Where Most Candidates Fail
Identity Resolution is the most architecturally complex component in Data Cloud, and it’s the area where exam preparation most often falls short. Candidates memorize that Identity Resolution produces a Unified Individual. They don’t internalize the mechanics that determine whether that Unified Individual is trustworthy.
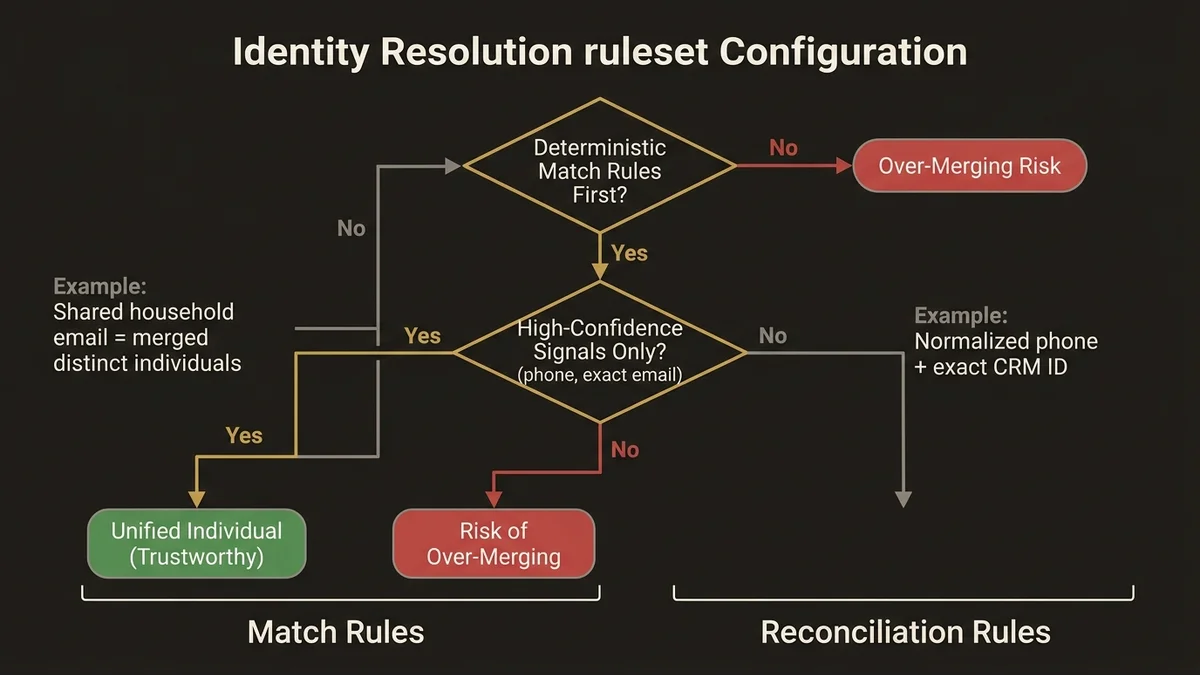
The critical architectural distinction is between match rules and reconciliation rules. Match rules determine which source records get grouped into a single Unified Individual. Reconciliation rules determine which field values from those source records win when there’s a conflict. These are separate decisions with separate consequences.
In practice, the failure mode is configuring aggressive fuzzy match rules on email or phone without understanding that a shared household email address will merge two distinct individuals into one profile. The exam tests this exact scenario. The correct answer is almost always to layer deterministic matching first (exact email, exact CRM ID) before introducing fuzzy rules, and to scope fuzzy rules to high-confidence signals like normalized phone numbers rather than name variants.
For deeper architectural treatment of how Identity Resolution rulesets interact with Data Model Objects, the article on Data Cloud identity resolution architecture covers the production patterns in detail.
Reconciliation rules deserve equal attention. When a contact exists in both a CRM Data Stream and a marketing platform Data Stream, the reconciliation rule determines which source’s email address, phone number, or consent flag takes precedence. Getting this wrong means your activation targets receive stale or incorrect contact data. The exam will present scenarios where you must identify which reconciliation configuration produces the correct outcome for a given business requirement.
Data Graphs and Calculated Insights: The Performance Architecture
A common gap in exam preparation is treating Data Graphs as an optional advanced topic. They’re not. Data Graphs are the mechanism that makes real-time profile access performant at scale.
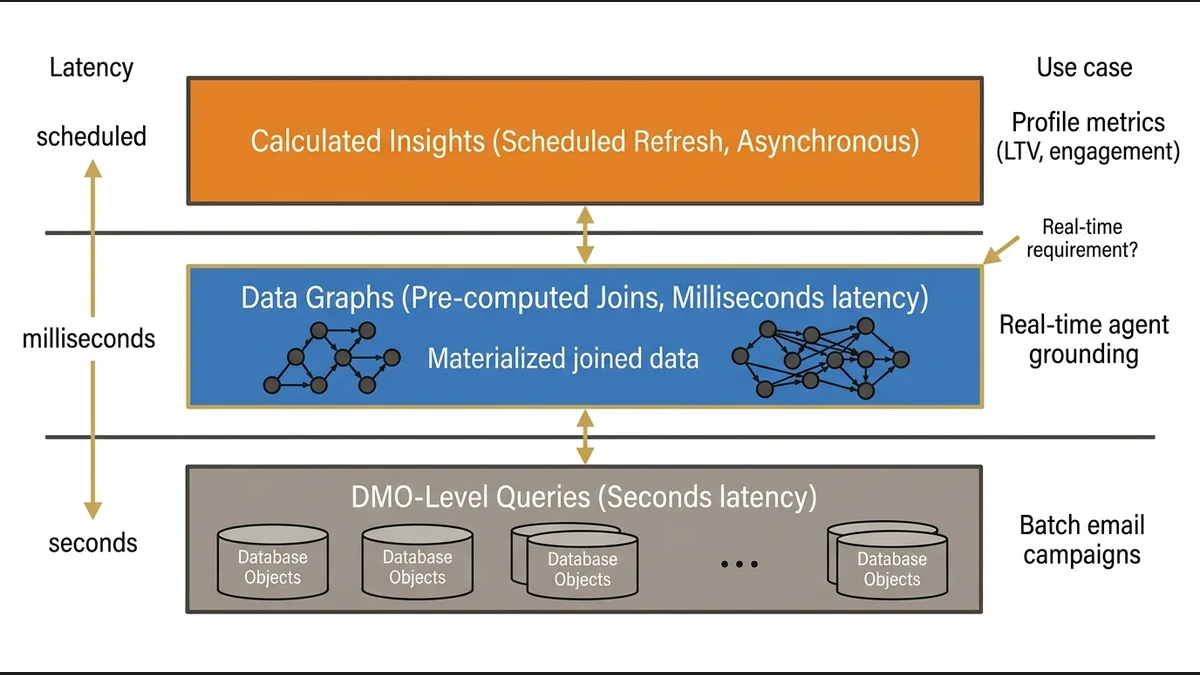
Without a Data Graph, querying a Unified Individual’s full profile requires joining across multiple DMOs at query time. At the scale of millions of profiles with dozens of related objects, that join latency is prohibitive for real-time use cases. Data Graphs pre-compute those joins and materialize the result, reducing query time from seconds to milliseconds.
The exam tests when to use a Data Graph versus querying DMOs directly. The answer depends on the use case: real-time agent grounding and next-best-action scenarios require Data Graphs; batch segmentation for email campaigns can tolerate DMO-level queries. Candidates who don’t understand this distinction will select the wrong architecture for scenario-based questions.
Calculated Insights operate at a different layer. They compute profile-level metrics (lifetime value, engagement score, purchase frequency) and store them as attributes on the Unified Individual. The architectural point the exam probes is that Calculated Insights run on a schedule, not in real time. If a use case requires a metric that reflects a transaction that happened 10 minutes ago, Calculated Insights won’t serve that requirement. The correct architecture is either a real-time Data Stream update or a Data Graph query against the raw transaction DMO.
Segmentation Architecture and Activation Targets
Segment design questions on the exam are less about the UI mechanics and more about the data model decisions that make segments reliable.
The most common trap: building a segment on attributes that live on a related DMO rather than on the Unified Individual or a Calculated Insight. Segments that traverse multiple DMO relationships at query time are slow and expensive. The correct pattern is to surface frequently-used segmentation attributes as Calculated Insights on the profile, then build segments against those pre-computed values.
Activation targets introduce a separate set of architectural considerations. The exam tests the difference between activation to a CRM target (writing back to Salesforce objects), activation to a cloud storage target (S3, Azure Blob), and activation to a marketing platform via a native connector. Each has different latency characteristics and different data freshness guarantees.
For real-time personalization use cases, the architecture that works is activating to a CRM target and triggering downstream Flow orchestration via Platform Events. Batch activation to cloud storage is appropriate for large audience exports to external systems but introduces hours of latency. Candidates who conflate these patterns will select wrong answers on scenario questions that specify latency requirements.
Preparing for the Agentforce Integration Domain
The integration between Data Cloud and Agentforce is now a meaningful portion of the exam, and it’s the area where most study materials are still catching up.
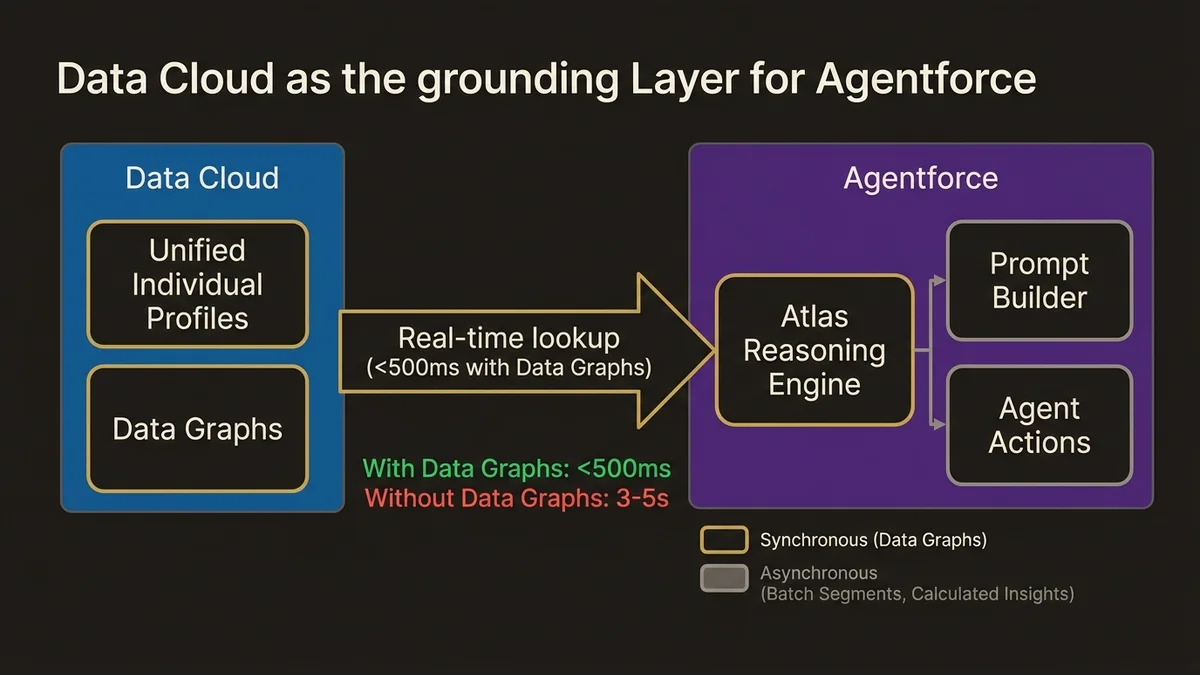
The core architectural concept is grounding: providing the Atlas Reasoning Engine with relevant, current profile data so agent responses are contextually accurate. Data Cloud serves as the grounding layer by exposing Unified Individual profiles and Data Graph outputs to Prompt Builder templates and agent Actions.
The exam tests the latency reality here. In enterprise deployments with standard Data Cloud configurations, the typical latency for a real-time Data Cloud profile lookup during an agent interaction is under 500 milliseconds when Data Graphs are properly configured. Without Data Graphs, that lookup can exceed 3-5 seconds, which is architecturally unacceptable for a synchronous customer interaction.
Expect questions about which Data Cloud components are appropriate for synchronous agent grounding (Data Graphs, Unified Individual attributes) versus which are appropriate only for asynchronous enrichment (Calculated Insights with scheduled refresh, batch Segments). The data-cloud-agentforce-foundation-architecture article covers this boundary in production terms.
For organizations building toward this architecture, the Data Cloud and Agentforce service pillar outlines the implementation approach.
Study Approach That Actually Works
Memorizing the Salesforce documentation is the wrong strategy. The exam is scenario-based, and scenarios require applied judgment.
The preparation approach that produces passing scores is working backward from failure modes. For each major component, understand what goes wrong when it’s misconfigured. What happens when Identity Resolution over-merges? What breaks when a Calculated Insight is used for a real-time requirement? What’s the consequence of building a Segment on a non-indexed DMO attribute at 50 million record scale?
Hands-on work in a developer org is non-negotiable. The concepts that seem abstract in documentation become concrete when you configure an Identity Resolution ruleset, watch it produce unexpected merges, and have to diagnose why. That diagnostic experience is exactly what the scenario questions are testing.
Trailhead’s Data Cloud learning paths cover the foundational mechanics. They’re necessary but not sufficient. Supplement with the official exam guide, which specifies the exact domain weightings, and with architecture-focused content that goes beyond feature descriptions into production tradeoffs.
Plan for 6-8 weeks of focused preparation if you have no prior Data Cloud hands-on experience. If you’ve worked on a Data Cloud implementation, 3-4 weeks of targeted exam preparation is realistic. The gap between “I’ve used Data Cloud” and “I understand why the architecture works this way” is where most experienced practitioners underestimate the exam.
Key Takeaways
- The Salesforce Data Cloud consultant certification tests architectural judgment on Identity Resolution, Data Graphs, and Calculated Insights, not feature memorization. Scenario questions require understanding failure modes, not definitions.
- Identity Resolution over-merging is architecturally worse than under-merging in most enterprise contexts. Always layer deterministic match rules before fuzzy rules, and scope fuzzy rules to high-confidence signals.
- Data Graphs are required for real-time use cases. Without pre-computed joins, profile lookup latency during synchronous agent interactions exceeds acceptable thresholds. This is a testable architectural distinction.
- Calculated Insights run on a schedule, not in real time. Any exam scenario requiring sub-minute metric freshness eliminates Calculated Insights as the correct answer.
- Agentforce integration questions now represent a meaningful exam domain. Understand the latency boundary between synchronous Data Graph lookups and asynchronous Segment activation before sitting the exam.
Need help with data 360 & multi-cloud architecture?
Unify customer data across Salesforce clouds with Data 360, build identity resolution models, and architect multi-cloud systems that actually work together.
Related Articles

Data Cloud Segmentation Strategy That Works
Most Data Cloud segmentation strategies fail before activation. Here's the architecture that prevents it, with specific patterns for enterprise orgs.

Data Cloud Integration: Sales & Service Cloud
How to architect Data Cloud integration with Sales and Service Cloud without creating a fragile, over-engineered mess. Patterns that hold at scale.

Customer 360 Data Cloud Architecture Patterns
Most Customer 360 Data Cloud implementations fail at the data model layer. Here's the architecture that actually works at enterprise scale.