

La déflexion de cas est la promesse commerciale numéro un d’Agentforce Service Cloud. C’est aussi l’endroit où la plupart des implémentations échouent silencieusement, en produisant des métriques flatteuses qui masquent une dégradation réelle de l’expérience client.
Pourquoi la déflexion mal architecturée coûte plus qu’elle ne rapporte
L’agentforce service cloud deflection cas repose sur un principe simple en apparence : intercepter les demandes entrantes avant qu’elles ne créent un enregistrement Case, les résoudre via un agent autonome, et ne remonter à un humain que si nécessaire. En pratique, la frontière entre “déflexion réussie” et “client frustré qui rappelle” est architecturale, pas fonctionnelle.
Le problème structurel que l’on observe dans les organisations avec des volumes de 50 000 cas mensuels ou plus : les équipes mesurent le taux de déflexion brut (conversations terminées sans Case créé) plutôt que le taux de résolution effective. Un agent qui répond “je n’ai pas trouvé d’information pertinente, souhaitez-vous être mis en relation ?” et que l’utilisateur ferme par frustration compte comme une déflexion réussie dans la plupart des configurations par défaut. C’est une illusion de performance.
L’architecture qui évite ce piège sépare trois états distincts : déflexion confirmée (problème résolu, client satisfait, signal explicite ou comportemental), escalade propre (Case créé avec contexte complet), et abandon non résolu (à traiter comme un échec, pas comme une déflexion).
L’architecture de déflexion qui tient en production
La couche de raisonnement d’Atlas Reasoning Engine détermine à chaque tour de conversation si l’agent dispose des informations suffisantes pour résoudre la demande. Ce n’est pas un simple matching d’intention : c’est une chaîne de raisonnement multi-étapes qui évalue la confiance de la réponse avant de la délivrer.
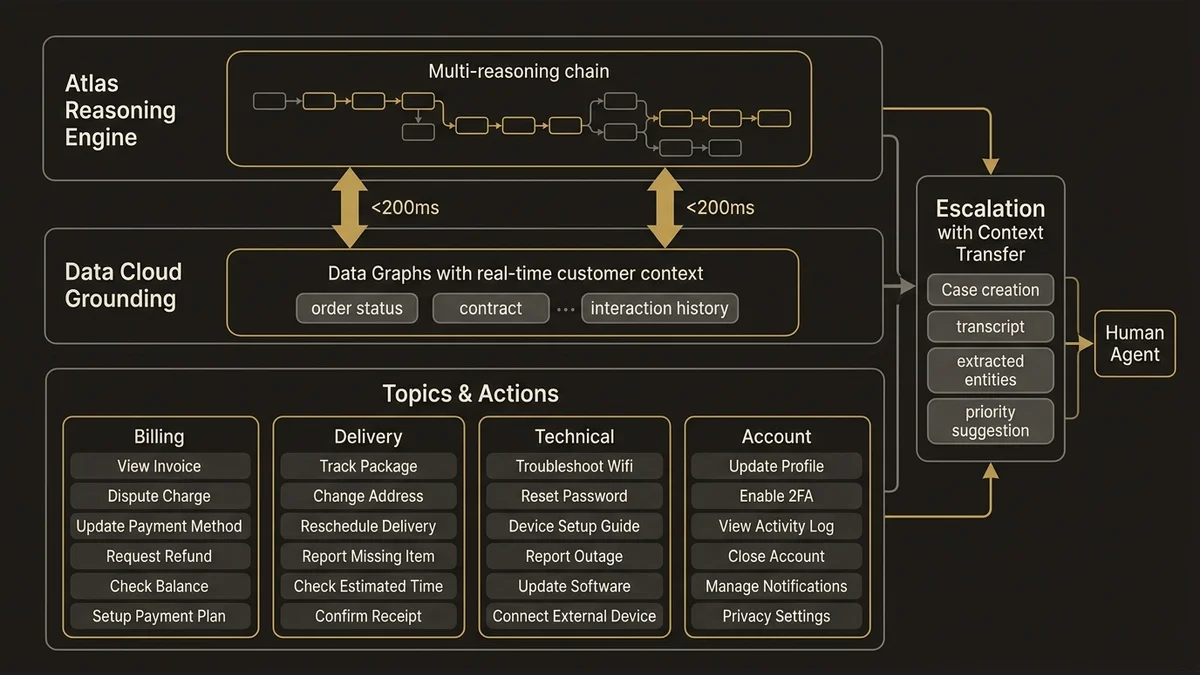
Pour que cette chaîne soit efficace, trois éléments doivent être en place simultanément.
Grounding sur Data Cloud. Un agent qui répond depuis une base de connaissances statique plafonne rapidement. L’architecture performante connecte l’Atlas Reasoning Engine à des Data Graphs matérialisés dans Data Cloud, qui exposent le contexte client en temps réel : historique des interactions, statut des commandes, contrats actifs, incidents en cours. La latence typique pour une activation Data Cloud en temps réel est de 2 à 5 minutes pour les mises à jour de profil, mais les Data Graphs pré-calculés réduisent le temps de requête à moins de 200ms au moment de la conversation. C’est la différence entre un agent qui dit “votre commande est en cours de traitement” et un agent qui dit “votre commande #47823 a été expédiée hier depuis Lyon, livraison prévue demain entre 14h et 18h”.
Topics et Actions correctement scopés. Une erreur fréquente consiste à créer un Topic trop large (“Support client général”) avec des dizaines d’Actions. Atlas Reasoning Engine performe mieux avec des Topics précis et des Actions atomiques. L’architecture recommandée : un Topic par domaine fonctionnel (facturation, livraison, technique, compte), chaque Topic contenant 5 à 8 Actions maximum, chaque Action ayant une description précise qui guide le moteur de raisonnement. Les Instructions au niveau du Topic définissent les limites de compétence et les conditions d’escalade.
Escalade avec transfert de contexte. Quand l’agent décide d’escalader, le Case créé doit contenir la transcription complète, les entités extraites (numéro de commande, type de problème, sentiment détecté), et une suggestion de priorité. Sans ce transfert, l’agent humain repart de zéro, et le client répète son problème. C’est le point de friction qui détruit la perception de valeur de l’automatisation.
Ce que la plupart des équipes font mal au démarrage
L’erreur d’architecture la plus commune : déployer Agentforce sur le canal digital en isolation, sans connecter les canaux voix et email dans la même logique de déflexion. Le résultat est prévisible. Les clients qui ne trouvent pas satisfaction sur le chat web appellent ou envoient un email, créant un Case que le système n’associe pas à la tentative de déflexion précédente. Le taux de déflexion affiché est élevé, le volume de cas réel ne baisse pas.
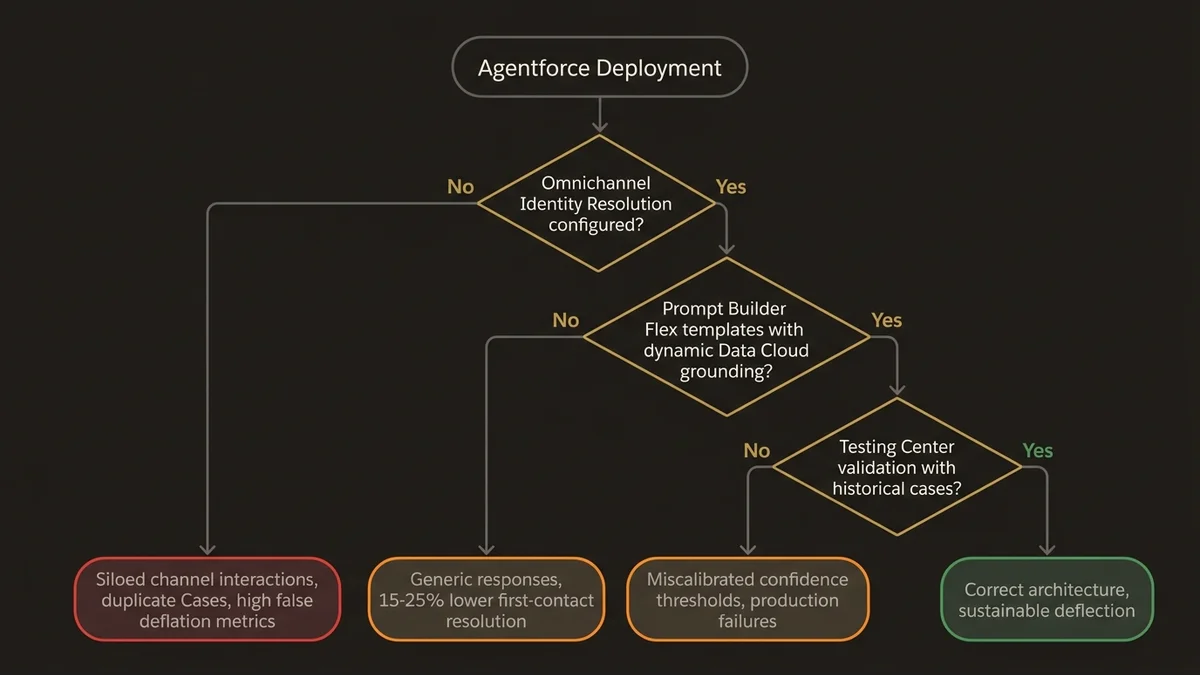
L’architecture omnicanale correcte utilise Identity Resolution de Data Cloud pour unifier les interactions cross-canal sur un Unified Individual avant de créer le Case. Si un client a déjà interagi avec l’agent web dans les 24 heures sur le même sujet, le Case entrant par email ou voix doit être enrichi de ce contexte, pas traité comme une demande nouvelle.
Deuxième erreur structurelle : négliger le Prompt Builder dans la configuration des réponses. Les templates de type Flex dans Prompt Builder permettent d’injecter dynamiquement le contexte Data Cloud dans les réponses de l’agent. Sans cette configuration, l’agent génère des réponses génériques qui ne tirent pas parti des données client disponibles. En pratique, les organisations qui configurent correctement les Flex templates observent une amélioration du taux de résolution au premier contact de 15 à 25 points de pourcentage par rapport à une configuration sans grounding dynamique.
Troisième erreur : ignorer l’Agentforce Testing Center avant le déploiement en production. Les scénarios de déflexion doivent être testés avec des cas réels historiques, pas des cas synthétiques. Le Testing Center permet de rejouer des conversations passées et de mesurer si l’agent aurait résolu le cas sans intervention humaine. C’est le seul moyen de calibrer les seuils de confiance d’Atlas Reasoning Engine avant d’exposer l’agent à des clients réels.
Pour aller plus loin sur la fondation Data Cloud nécessaire à ces patterns, l’article sur l’architecture Data Cloud et Agentforce détaille les dépendances techniques entre les deux plateformes.
Mesurer la déflexion réelle, pas la déflexion déclarée
Le KPI qui compte n’est pas le taux de déflexion brut. C’est le taux de résolution sans contact humain ultérieur sur une fenêtre de 48 heures. Un client qui interagit avec l’agent, ne crée pas de Case, mais rappelle le lendemain n’a pas été défléchi : il a été différé.
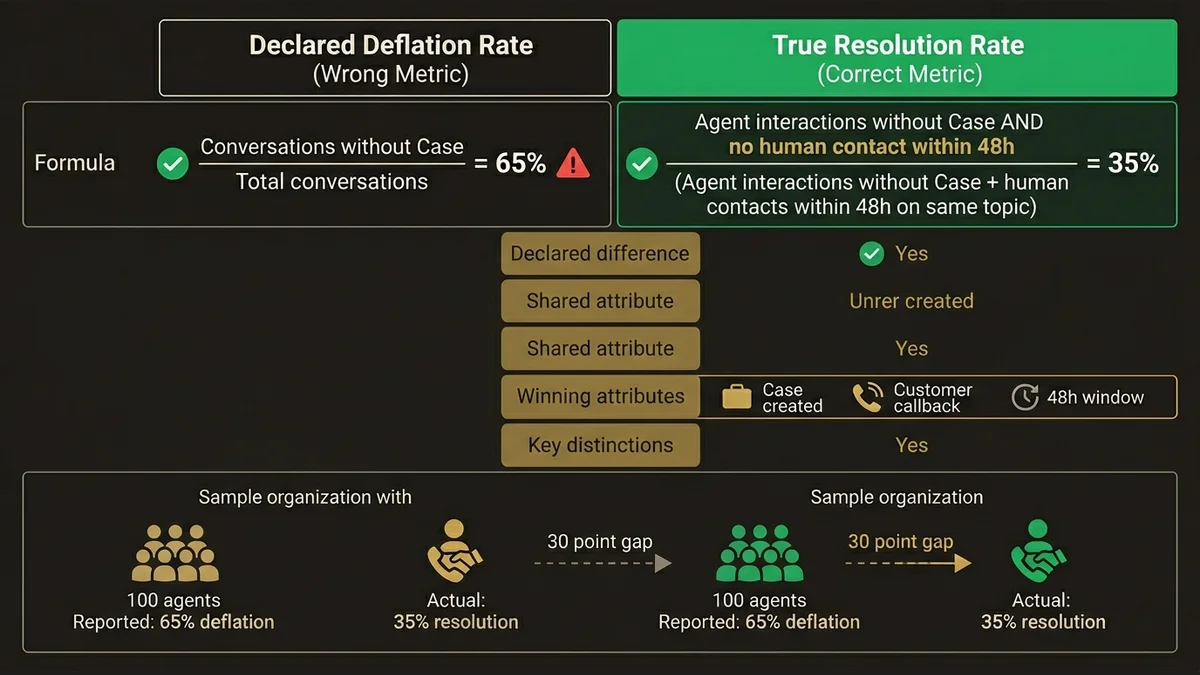
L’architecture de mesure correcte s’appuie sur les Calculated Insights de Data Cloud pour calculer ce taux de résolution effective. La formule : interactions agent terminées sans Case / (interactions agent terminées sans Case + contacts humains dans les 48h sur le même sujet pour le même Unified Individual). Ce calcul nécessite que l’Identity Resolution soit correctement configurée et que les interactions agent soient ingérées dans Data Cloud via des Data Streams dédiés.
Dans les organisations avec des équipes support de 100 agents ou plus, ce KPI révèle systématiquement un écart de 20 à 35 points entre le taux de déflexion déclaré et le taux de résolution effective. C’est cet écart qui doit piloter les itérations d’architecture, pas les tableaux de bord de déflexion brute.
Les décisions prises aujourd’hui sur la granularité des Topics, la qualité du grounding Data Cloud, et la configuration des seuils d’escalade déterminent si Agentforce devient un levier de réduction de coût durable ou un projet pilote qui stagne à 30% de déflexion effective. La fenêtre pour bien architecturer est au démarrage : reconfigurer des Topics mal scopés après six mois de production avec des données d’entraînement accumulées est significativement plus coûteux que de le faire correctement dès le départ.
Pour les organisations qui envisagent de déployer Agentforce dans un contexte de service client complexe, les détails sur les choix d’architecture sont disponibles sur la page architecture Agentforce.
Points Clés
- La déflexion de cas Agentforce Service Cloud doit être mesurée comme taux de résolution sans contact humain dans les 48h, pas comme taux de conversations sans Case créé. L’écart entre les deux est typiquement de 20 à 35 points dans les équipes support de 100 agents ou plus.
- L’Atlas Reasoning Engine performe mieux avec des Topics précis (un par domaine fonctionnel) et des Actions atomiques (5 à 8 par Topic), plutôt qu’avec des Topics larges et des Actions génériques.
- Le grounding sur Data Cloud via des Data Graphs pré-calculés réduit le temps de requête à moins de 200ms et permet des réponses contextualisées qui augmentent le taux de résolution au premier contact de 15 à 25 points par rapport à une configuration sans grounding dynamique.
- L’Identity Resolution de Data Cloud est un prérequis pour une déflexion omnicanale réelle : sans unification cross-canal sur un Unified Individual, les clients non résolus sur le web créent des Cases par email ou voix qui ne sont pas comptabilisés comme échecs de déflexion.
- L’Agentforce Testing Center doit être utilisé avec des cas historiques réels avant tout déploiement en production pour calibrer les seuils de confiance d’Atlas Reasoning Engine.
