

Les ETI françaises n’ont pas les moyens d’une refonte système pour adopter l’IA agentique. Spring ‘26 change la donne, mais pas de la façon dont Salesforce le présente dans ses keynotes.
La vraie question n’est pas “quelles nouvelles fonctionnalités Agentforce ?” mais “comment l’Agentforce Architecture de Spring ‘26 s’intègre dans un SI fragmenté, avec des données distribuées entre trois ERP, un CRM vieillissant et des contraintes RGPD non négociables ?” C’est précisément là que la release apporte des réponses concrètes, et là aussi qu’elle crée de nouveaux pièges.
Ce que Spring ‘26 change réellement dans le modèle de données agentique
La release introduit une évolution structurelle dans la façon dont les agents consomment les données : les Data Graphs de Data Cloud deviennent des sources natives pour l’Atlas Reasoning Engine. Ce n’est pas un détail de configuration. C’est un changement de paradigme.
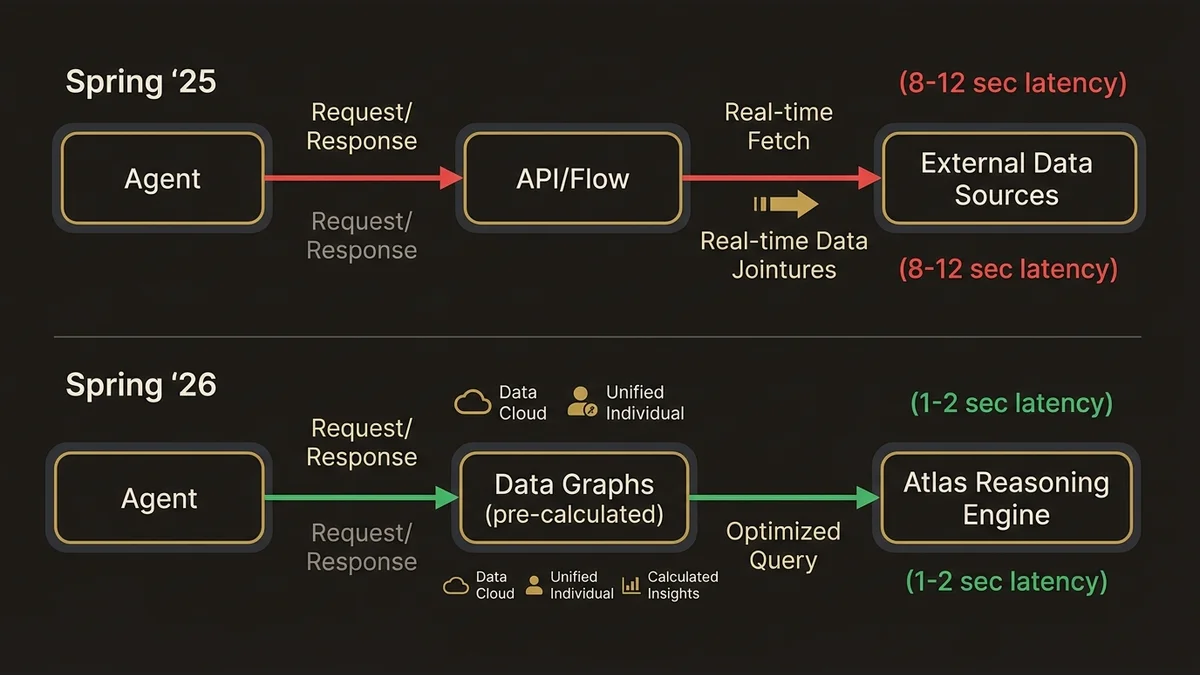
Jusqu’à Spring ‘25, un agent Agentforce qui avait besoin d’un contexte client enrichi devait passer par une Action qui appelait une API externe ou un Flow qui interrogeait des objets Salesforce standard. La latence était acceptable pour des cas d’usage simples, mais dès qu’on ajoutait des jointures entre Unified Individual, des Calculated Insights et des données transactionnelles, les temps de réponse dépassaient les 8-12 secondes, ce qui rendait l’expérience conversationnelle inutilisable.
Avec Spring ‘26, les Data Graphs pré-calculés servent de couche de matérialisation entre Data Cloud et l’Atlas Reasoning Engine. En pratique, pour une ETI avec 500 000 profils clients unifiés, la latence de récupération du contexte tombe à 1-2 secondes. Ce n’est pas de la magie : c’est parce que les jointures complexes sont calculées en amont, pas à la volée lors de chaque inférence.
Pour les DSI d’ETI françaises, cela signifie que le prérequis n’est plus “avoir une architecture de données parfaite” mais “avoir des Data Graphs correctement définis”. C’est une barre beaucoup plus accessible.
L’architecture qui fonctionne pour les SI fragmentés des ETI
Une ETI française typique dans le retail ou l’industrie opère avec des données client réparties entre un ERP (souvent SAP ou Sage), un CRM Salesforce parfois mal alimenté, et des données comportementales dans un outil analytics tiers. L’Identity Resolution de Data Cloud peut unifier ces sources, mais la vraie difficulté est en amont : les Data Streams doivent être configurés pour ingérer des données dont la qualité est inégale.
L’architecture qui fonctionne ici suit un principe de tolérance à l’imperfection. Plutôt que d’attendre une gouvernance des données parfaite avant de déployer des agents, on structure les Data Model Objects (DMOs) pour absorber les incohérences. Les rulesets d’Identity Resolution sont configurés avec des seuils de confiance explicites : un match à 85% sur nom + email + code postal est traité différemment d’un match à 60% sur nom seul. L’agent reçoit ce niveau de confiance comme contexte et adapte ses réponses en conséquence.
Spring ‘26 renforce cette approche en permettant aux Topics d’un agent de référencer directement le score de confiance d’un Unified Individual. Concrètement, un agent de service client peut désormais dire “je vois deux profils potentiels pour ce client, lequel est le bon ?” plutôt que de choisir silencieusement le mauvais et générer une réponse incorrecte.
Pour les ETI qui démarrent avec Agentforce, l’article sur l’unification des données avant le déploiement reste la référence pour séquencer correctement ces étapes.
RGPD et agents IA : les nouveaux vecteurs de risque de Spring ‘26
Spring ‘26 introduit des capacités de mémoire persistante pour les agents, ce qui est architecturalement puissant et juridiquement risqué pour le marché français.

La mémoire persistante permet à un agent de se souvenir des préférences et du contexte d’interactions précédentes sans que l’utilisateur ait à tout réexpliquer. Du point de vue UX, c’est une amélioration significative. Du point de vue RGPD, c’est un nouveau type de traitement de données personnelles qui nécessite une base légale explicite, une durée de conservation définie et un mécanisme de suppression sur demande.
Le problème architectural concret : cette mémoire est stockée dans des objets Salesforce standard (Agent Memory Records), mais les politiques de rétention de données de la plupart des ETI françaises n’ont pas été conçues pour ce type d’objet. En pratique, les DSI découvrent souvent cette lacune lors d’un audit RGPD post-déploiement, pas avant.
La bonne approche est de traiter les Agent Memory Records comme des données personnelles dès la conception. Cela implique de les inclure dans le registre des traitements, de configurer des règles d’archivage automatique via Flow, et de s’assurer que le droit à l’effacement peut être exercé sans intervention manuelle. Ce n’est pas complexe techniquement, mais ça doit être fait avant le go-live, pas après.
Un deuxième vecteur de risque : les External Services appelés par les agents. Spring ‘26 facilite l’intégration d’APIs externes dans les Actions d’un agent. Pour une ETI qui connecte son agent à un système de gestion des commandes ou à un outil de scoring crédit, chaque appel externe est potentiellement un transfert de données hors du périmètre Salesforce. Les DSI doivent cartographier ces flux dans leur analyse d’impact (DPIA) et s’assurer que les sous-traitants concernés sont couverts par des clauses contractuelles conformes.
Déploiement sans rupture : le séquençage qui évite les régressions
Le risque principal pour une ETI qui déploie Agentforce sur un SI existant n’est pas l’échec du projet IA. C’est la régression silencieuse sur les processus métier existants.
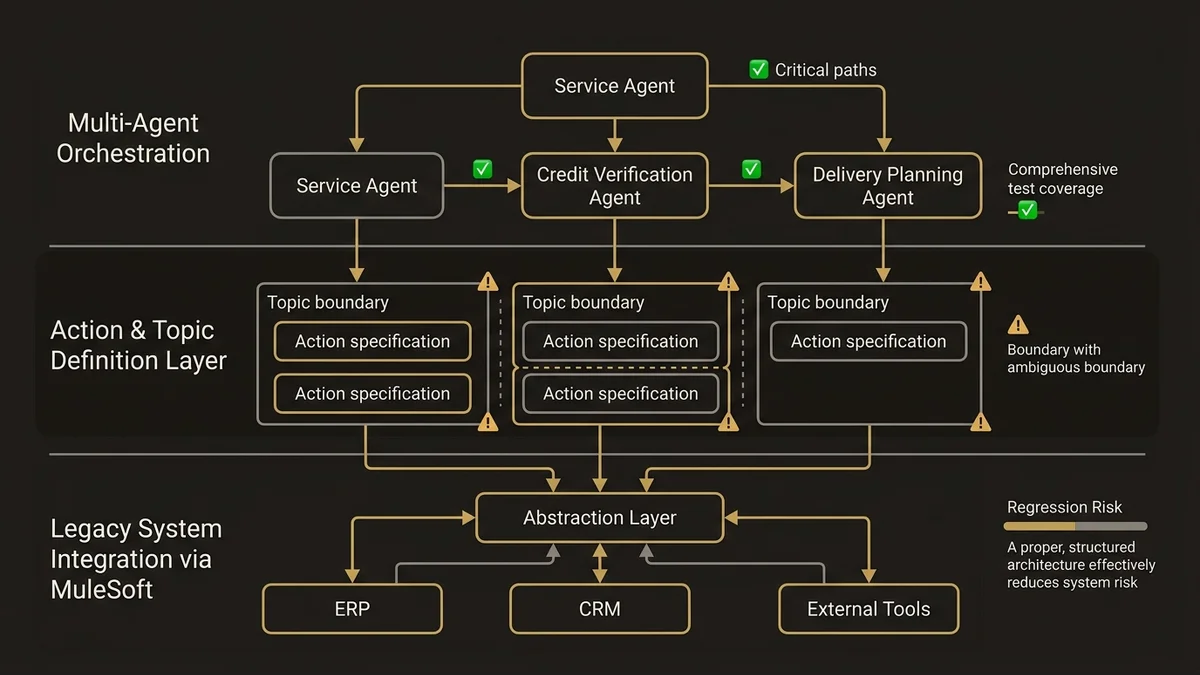
Spring ‘26 introduit des capacités d’orchestration multi-agents où un agent peut déléguer des sous-tâches à d’autres agents spécialisés. C’est puissant pour des cas d’usage complexes (qualification commerciale + vérification crédit + planification livraison), mais cela crée des dépendances entre agents qui peuvent casser des workflows existants si un agent est modifié sans considérer ses dépendances.
L’architecture qui évite ce problème repose sur trois principes. D’abord, chaque agent est défini avec des Topics et des Instructions suffisamment précis pour que son périmètre soit non ambigu. Un agent “gestion des retours” ne doit pas pouvoir dériver vers des actions de remboursement si ce processus est géré par un système externe avec ses propres contrôles. Ensuite, les Actions critiques sont testées systématiquement via l’Agentforce Testing Center avant chaque mise en production, avec des scénarios qui couvrent les cas limites, pas seulement le happy path. Enfin, les intégrations avec les systèmes legacy passent par MuleSoft comme couche d’abstraction, ce qui permet de modifier le système cible sans reconfigurer l’agent.
Ce séquençage est particulièrement important pour les ETI qui opèrent avec des équipes IT réduites. Une ESN qui déploie Agentforce pour une ETI sans cette rigueur architecturale crée une dette technique qui se manifeste 6 à 12 mois après le go-live, quand les premiers agents doivent être mis à jour et que personne ne comprend plus les dépendances.
Pour aller plus loin sur l’architecture de déploiement Agentforce, la page /services/agentforce-architecture détaille les patterns de gouvernance adaptés aux contraintes des ETI françaises.
La décision à prendre maintenant
Spring ‘26 crée une fenêtre d’opportunité réelle pour les ETI françaises. Les Data Graphs comme source native pour l’Atlas Reasoning Engine réduisent significativement la complexité d’intégration. La maturité des rulesets d’Identity Resolution permet de travailler avec des données imparfaites. Les capacités multi-agents ouvrent des cas d’usage qui n’étaient pas viables il y a 12 mois.
Mais cette fenêtre a une condition préalable : la gouvernance des données doit être traitée comme un prérequis architectural, pas comme un chantier parallèle. Les ETI qui déploient des agents sur des données non gouvernées en Spring ‘26 auront des agents qui fonctionnent en démo et échouent en production.
Le choix n’est pas “déployer maintenant ou attendre”. C’est “déployer avec la bonne fondation ou accumuler une dette qui coûtera trois fois plus cher à corriger dans 18 mois”. Les organisations qui ont structuré leurs Data Streams et leurs DMOs correctement avant Spring ‘26 peuvent déployer des agents opérationnels en 8 à 12 semaines. Celles qui ne l’ont pas fait ont d’abord un chantier de données, pas un chantier IA.
Points Clés
- Les Data Graphs de Data Cloud deviennent sources natives pour l’Atlas Reasoning Engine dans Spring ‘26, réduisant la latence de contexte de 8-12 secondes à 1-2 secondes pour les profils unifiés.
- L’Agentforce Architecture viable pour les ETI françaises repose sur une tolérance à l’imperfection des données, pas sur une gouvernance parfaite en prérequis absolu.
- La mémoire persistante des agents introduite dans Spring ‘26 crée de nouveaux traitements de données personnelles qui doivent être intégrés au registre RGPD avant le go-live.
- L’orchestration multi-agents nécessite une définition stricte des Topics et des tests systématiques via l’Agentforce Testing Center pour éviter les régressions sur les processus existants.
- Les ETI avec des Data Streams et DMOs correctement configurés peuvent atteindre un déploiement opérationnel en 8 à 12 semaines sur Spring ‘26, contre 6 mois ou plus pour celles qui partent de zéro.
