

La question revient systématiquement dans les comités d’architecture : faut-il passer par Data Cloud ou MuleSoft pour unifier les données Salesforce ? Le débat est mal posé, et c’est précisément là que les projets dérivent.
Le salesforce data cloud vs mulesoft choix architecture n’est pas une question de préférence technologique. C’est une question de responsabilité fonctionnelle. Ces deux plateformes résolvent des problèmes fondamentalement différents, et les confondre génère soit une sur-ingénierie coûteuse, soit une architecture qui tient jusqu’au premier pic de charge.
Ce que chaque plateforme résout réellement
MuleSoft est une couche d’intégration. Son rôle est de faire circuler des données entre systèmes hétérogènes, de transformer des formats, d’orchestrer des appels API, de gérer les erreurs de transport. C’est un bus d’entreprise moderne avec une gouvernance API intégrée. Il excelle quand le problème est : “comment faire parler un ERP SAP avec Salesforce Sales Cloud et un système de facturation legacy en temps réel ?”
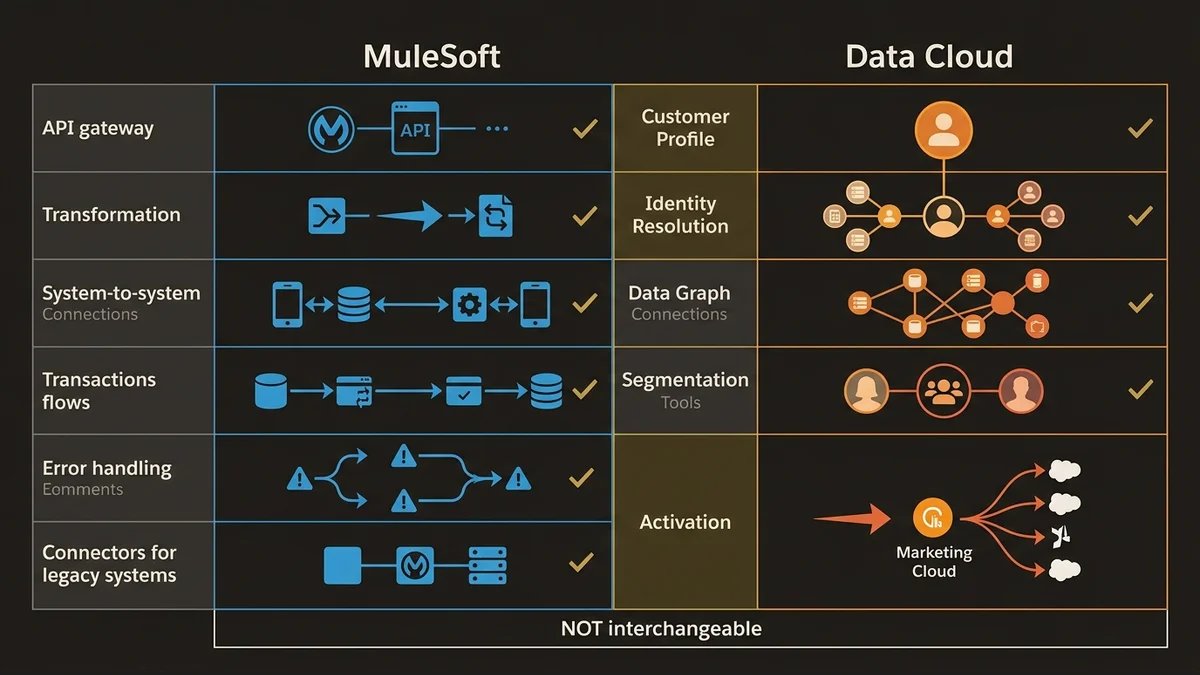
Data Cloud est une plateforme de données client. Son rôle est d’ingérer, d’unifier, de segmenter et d’activer des profils. L’Identity Resolution construit des Unified Individuals à partir de sources fragmentées. Les Data Graphs matérialisent des jointures pré-calculées pour alimenter Agentforce ou des Calculated Insights. Ce n’est pas un bus d’intégration. C’est un moteur de connaissance client.
La confusion vient du fait que les deux plateformes peuvent techniquement ingérer des données depuis des systèmes externes. Mais “pouvoir faire” n’est pas “devoir faire”.
Quand MuleSoft est l’architecture correcte
MuleSoft s’impose quand le problème est transactionnel et bidirectionnel. Trois patterns le justifient clairement.
Le premier : l’orchestration de processus métier cross-systèmes. Une commande créée dans Salesforce Commerce Cloud doit déclencher une réservation de stock dans l’ERP, une création de dossier dans Service Cloud, et une notification dans le système logistique. Ce flux nécessite une gestion d’erreur fine, des compensations en cas d’échec partiel, et une traçabilité par transaction. Data Cloud n’a pas vocation à gérer ce type d’orchestration.
Le deuxième : l’intégration legacy avec transformation complexe. Les systèmes mainframe ou les ERP ancienne génération exposent des formats propriétaires (COBOL copybooks, EDI, XML non standard). MuleSoft dispose des connecteurs et des capacités de transformation DataWeave pour absorber cette complexité. Data Cloud s’appuie sur des Data Streams structurés, pas sur des transformations de format arbitraires.
Le troisième : la gouvernance API à l’échelle de l’entreprise. Dans les organisations avec plus de 50 systèmes interconnectés, Anypoint Platform fournit un catalogue API, des politiques de sécurité centralisées, et une observabilité des flux. C’est une infrastructure de plateforme, pas un outil de données.
Pour aller plus loin sur les patterns d’intégration multi-cloud, l’article Intégration multi-cloud Salesforce et MuleSoft détaille les décisions d’architecture qui structurent ces choix.
Quand Data Cloud est l’architecture correcte
Data Cloud s’impose quand le problème est analytique, unificateur, et orienté activation. Là encore, trois patterns sont déterminants.
Le premier : la résolution d’identité à grande échelle. Dans les organisations avec plusieurs millions de contacts répartis sur des canaux distincts (e-commerce, point de vente, service client, programme de fidélité), l’Identity Resolution de Data Cloud construit des Unified Individuals via des rulesets configurables. Un même client peut avoir cinq adresses email différentes selon le canal. MuleSoft ne résout pas ce problème structurellement. Il peut transporter les données, mais pas unifier les identités.
Le deuxième : l’alimentation d’Agentforce avec un contexte client riche. L’Atlas Reasoning Engine d’Agentforce consomme des Data Graphs pour raisonner sur le profil complet d’un client. Si les données sont dispersées dans des systèmes silotés sans unification préalable, l’agent opère à l’aveugle. Data Cloud est la fondation obligatoire pour tout déploiement Agentforce sérieux. Ce n’est pas optionnel.
Le troisième : la segmentation et l’activation temps réel. Les Segments Data Cloud alimentent directement Marketing Cloud, les Calculated Insights enrichissent les scores de propension, et les activations vers des plateformes publicitaires externes se font nativement. MuleSoft peut techniquement faire transiter ces données, mais sans la couche sémantique des Data Model Objects, chaque activation devient un projet d’intégration à part entière.
L’architecture qui fonctionne en pratique
La réponse correcte n’est pas “l’un ou l’autre”. C’est “chacun à sa place dans la chaîne de valeur”.
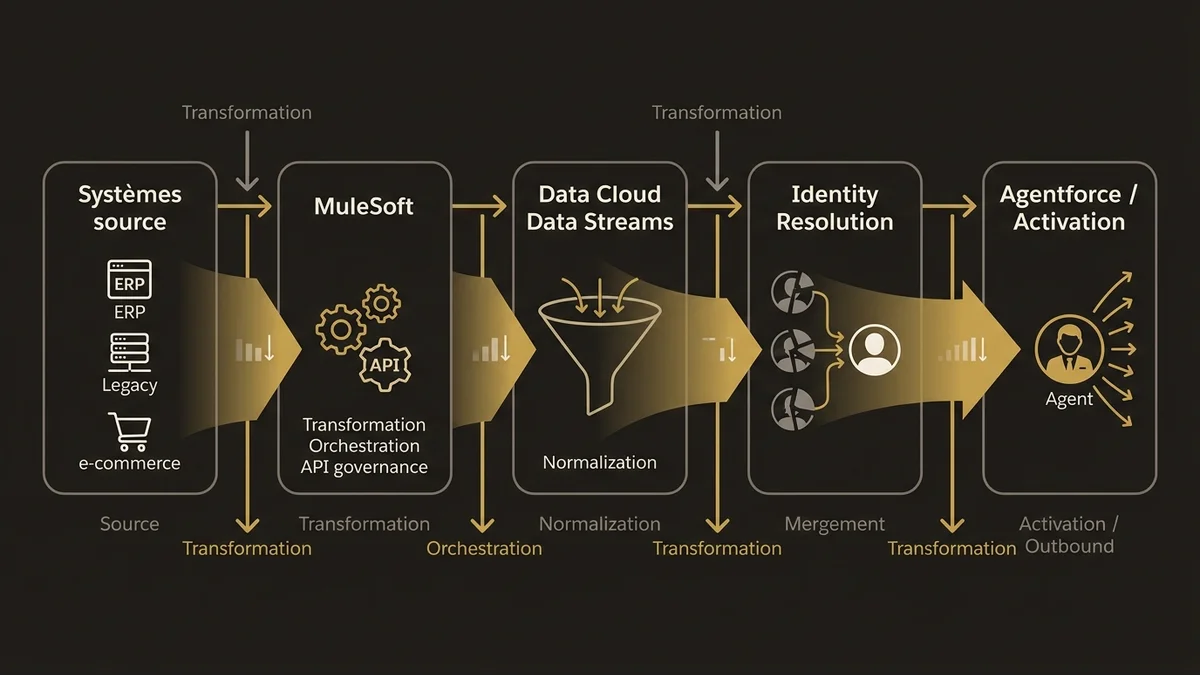
L’architecture qui tient à l’échelle ressemble à ceci : MuleSoft gère les flux transactionnels et les intégrations legacy en amont. Il normalise et achemine les données vers Data Cloud via des Data Streams structurés. Data Cloud prend en charge l’unification, la résolution d’identité, et l’activation. Agentforce consomme les Data Graphs résultants pour opérer avec un contexte complet.
Systèmes source (ERP, legacy, e-commerce)
↓
MuleSoft (transformation, orchestration, gouvernance API)
↓
Data Cloud Data Streams (ingestion normalisée)
↓
Identity Resolution → Unified Individual
↓
Data Graphs + Calculated Insights
↓
Agentforce / Marketing Cloud / Activations externesDans les organisations avec plus de 3 000 points de contact retail, cette séparation des responsabilités est non négociable. Tenter de faire faire à Data Cloud le travail de MuleSoft sur des flux transactionnels complexes génère des Data Streams instables et une dette technique qui se révèle lors des montées en charge. Tenter de faire faire à MuleSoft le travail de Data Cloud sur l’unification des profils produit des pipelines sur-mesure impossibles à maintenir.
La latence typique pour l’activation Data Cloud en temps réel, une fois l’architecture correctement dimensionnée, est de 2 à 5 minutes. Si vous observez des latences supérieures à 10 minutes, le problème est presque toujours en amont : des Data Streams mal configurés ou une transformation qui aurait dû être faite dans MuleSoft avant l’ingestion.
Les erreurs d’architecture les plus fréquentes
La première erreur est de choisir en fonction du budget disponible plutôt que du problème à résoudre. Data Cloud a un coût de licence significatif. Certaines DSI tentent de le remplacer par des flux MuleSoft complexes qui répliquent une logique d’unification maison. Le résultat est invariablement un système fragile, non gouverné, et impossible à faire évoluer quand les cas d’usage IA arrivent.
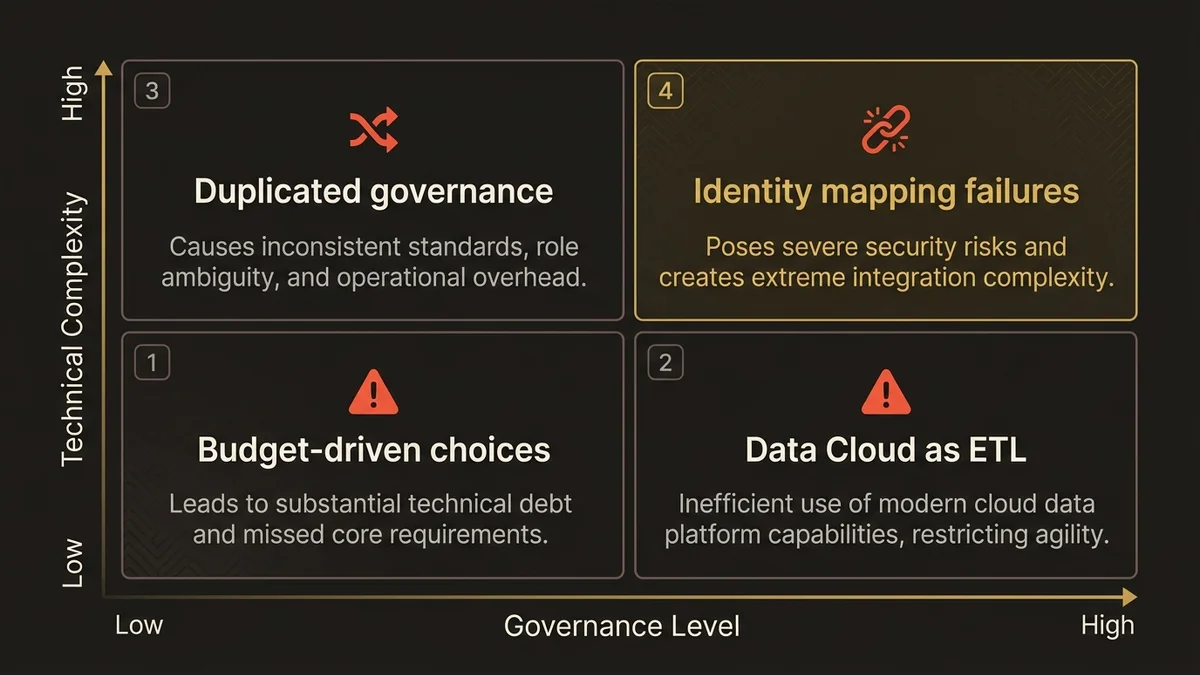
La deuxième erreur est d’utiliser Data Cloud comme un ETL. Les Data Streams ne sont pas des pipelines de transformation. Ingérer des données brutes non normalisées dans Data Cloud pour les transformer ensuite via des formules Calculated Insights est une mauvaise utilisation de la plateforme. La transformation doit se faire en amont, dans MuleSoft ou dans la couche source.
La troisième erreur est de dupliquer la gouvernance. Certaines architectures maintiennent un catalogue API dans MuleSoft Anypoint ET une gouvernance des Data Streams dans Data Cloud sans cohérence entre les deux. Le résultat est une opacité totale sur la lignée des données, ce qui devient un problème RGPD sérieux lors des audits.
La quatrième erreur concerne la gestion des identifiants. MuleSoft transporte souvent des identifiants techniques (IDs ERP, IDs e-commerce) sans les mapper vers des identifiants métier cohérents. Quand ces données arrivent dans Data Cloud, les rulesets d’Identity Resolution ne peuvent pas travailler correctement. La résolution d’identité commence dans la conception des flux MuleSoft, pas dans la configuration Data Cloud.
Pour une analyse détaillée de l’architecture Data Cloud et de ses patterns d’implémentation, la page Architecture Data Cloud et Multi-Cloud couvre les décisions structurantes de ce type de projet.
Points Clés
- MuleSoft résout les problèmes d’intégration transactionnelle et de gouvernance API. Data Cloud résout les problèmes d’unification de profil et d’activation. Les confondre génère une dette architecturale immédiate.
- L’architecture correcte positionne MuleSoft en amont pour normaliser les flux, et Data Cloud en aval pour unifier et activer. Ce n’est pas une alternative, c’est une séquence.
- L’Identity Resolution de Data Cloud nécessite des identifiants propres en entrée. Si les Data Streams reçoivent des IDs techniques non mappés depuis MuleSoft, les Unified Individuals seront fragmentés et inutilisables pour Agentforce.
- Une latence d’activation Data Cloud supérieure à 10 minutes signale presque toujours un problème de conception des Data Streams, pas un problème de capacité plateforme.
- Tout déploiement Agentforce sérieux présuppose Data Cloud comme fondation. Tenter de construire des agents sur des données non unifiées produit des expériences client incohérentes et des hallucinations contextuelles.
